Person: PICK UP A BIG RED BLOCK.
Computer: OK. (does it)
Person: GRASP THE PYRAMID.
Computer: I DON'T UNDERSTAND WHICH PYRAMID YOU MEAN.
The area of natural language and speech processing covers algorithms for three types of tasks:
In the first two cases, a system might contain a complete end-to-end pipeline (e.g. speech to structured information). But it's also common for see applications that do only part of it, e.g. transcribing speech into written text. A human then takes over (e.g. reads and understands the transcripts). Generation is easier than understanding, but still hard to do well.
Interactive systems using natural language have been around since the early days of AI and computer games. For example:
These older systems used simplified text input. The computer's output seems to be sophisticated, but actually involves a limited set of generation rules stringing together canned text. Most of the sophistication is in the backend world model. This enabled the systems to carry on a coherent dialog.
These systems also depend on social engineering: teaching the user what they can and cannot understand. People are very good at adapting to a system with limited, but consistent, linguistic skills.
A "shallow" system converts fairly directly between its input and output, e.g. a translation system that transforms phrases into new phrases without much understanding of what the input means. A "deep" system uses a high-level representation as an intermediate step between its input and output. There is no hard-and-fast boundary between the two types of design. Both approaches can be useful in an appropriate context.
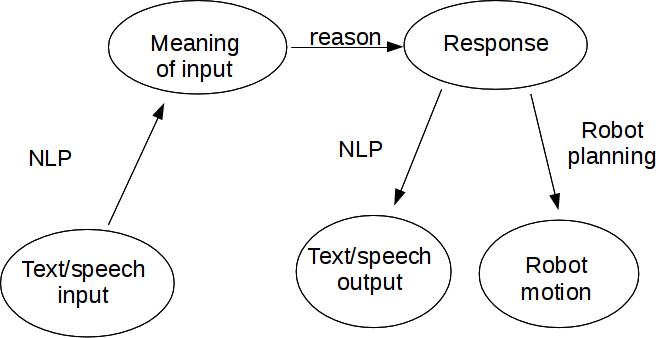 A deep system
A deep system
In classical AI systems, the high-level representation might look like mathematical logic. E.g.
in(Joe,kitchen) AND holding(Joe,cheese)
Or perhaps we have a set of objects and events, each containing values for a number of named slots:
event
name = "World War II"
type = war
years = (1939 1945)
participants = (Germany, France, ....)
In modern systems based on neural nets, the high-level representation may look partly like a set of mysterious floating-point numbers. But these are intended to represent information at much the same level as the symbolic representations of meaning.
Many of the useful current AI systems are shallow. That is, they process their input with little or no understanding of what it actually means. For example, suppose that you ask Google "How do I make zucchini kimchi?" or "Are tomatoes fruits?" Google doesn't actually answer the question but, instead, returns some paragraphs that seem likely to contain the answer. Shallow tools work well primarily because of the massive amount of data they have scraped off the web.
Similarly, summarization systems are typically shallow. These systems combine and select text from several stories, to produce a single short abstract. The user may read just the abstract, or decide to drill down and read some/all of the full stories. Google news is a good example of a robust summarization system. These systems make effective use of shallow methods, depending on the human to finish the job of understanding.
Text translations systems are often surprisingly shallow, with just enough depth of representation to handle changes in word order between languages.
Google translate is impressive, but can also fail catastrophically. A classic test is a circular translation: X to Y and then back to X. Google translate sweeps up text from the entire internet but can still be made to fail. It's best to pick somewhat uncommon topics (making kimchi, Brexit) and/or a less-commmon language, so that the translation system can't simply regurgitate memorized chunks of text.
Here is a Failure created by translating into a less-common language (Zulu) and back into English:
A serious issue with current AI systems is that they have no idea when they are confused. A human is more likely to understand that they don't know the answer, and say so rather than bluffing.
Deeper processing has usually been limited to focused domains, for which we can easily convert text or speech into a representation for underlying meaning. A simple example would when Google returns structured information for a restaurant, e.g. its address and opening hours. In this case, the hard part of the task is extracting the structured information from web pages, because people present this information in many different formats. It's typically much easier to generate natural language text, or even speech, from structured representations.
End-to-end systems have been built for some highly-structured customer service tasks, e.g. speech-based airline reservations (a task that was popular historically in AI) or utility company help lines. Google had a recent demo of a computer assistant making a restaurant reservation by phone. There have also been demo systems for tutoring, e.g. physics.
Many of these systems depend on the fact that people will adapt their language when they know they are talking to a computer. It's often critical that the computer's responses not sound too sophisticated, so that the human doesn't over-estimate its capabilities. (This may have happened to you when attempting a foreign language, if you are good at mimicking pronunciation.) These systems often steer humans towards using certain words. E.g. when the computer suggests several alternatives ("Do you want to report an outage? pay a bill?") the human is likely to use similar words in their reponse.
If the AI system is capable of relatively fluent output (possible in a limited domain), the user may mistakenly assume it understands more than it does. Many of us have had this problem when travelling in a foreign country: a simple question pronounced will may be answered with a flood of fluent language that can't be understood. Designers of AI systems often include cues to make sure humans understand that they're dealing with a computer, so that they will make appropriate allowances for what it's capable of doing.