MP 1: Introduction to Linux Kernel Programming
Goals and Overview
- In this Machine problem you will learn the basics of Linux Kernel Programming
- You will learn to create a Linux Kernel Module (LKM).
- You will use Timers in the Linux Kernel to schedule work
- You will use Workqueues to defer work through the use of the Two-Halves concept
- You will use the basics of the Linked Lists interface in the Linux Kernel to temporarily store data in the kernel
- You will learn the basic of Concurrency and Locking in the Linux Kernel
- You will interface applications in userspace with your Kernel Module through the Proc Filesystem
Extra Credit Checkpoints
You can earn extra credit by starting on this MP early:
- EC Checkpoint 1: Complete Steps 1 and 2 by Monday, Feb. 15 at 11:59pm for +5 points.
- EC Checkpoint 2: Complete Steps 1-8 by Monday, Feb. 22 at 11:59pm for +5 points.
Introduction
Kernel Programming has some particularities that can make it more difficult to debug and learn. In this section we will discuss a few of them.
The most important difference between kernel programming in Linux and Application programming in userspace is the lack of Memory Protection. That is driver, modules, and kernel threads all share the same memory address space. De-referencing a pointer that contains the wrong memory location and writing to it can cause the whole system to crash or corrupt important subsystems including filesystem and networking.
Another important difference is that in kernel programming, preemption is not always available, that means that we can indefinitely hog the CPU or cause system-wide deadlocks. This makes concurrency much more difficult to handle in the kernel than in userspace. For example in kernelspace we are responsible for ensuring that interrupt handlers are as efficient as possible using the CPU for very little time.
Yet another important issue is the lack of userspace libraries. Glib, C++ Standard Library and other libraries reside in userspace and cannot be accessed in the kernel. This limits what we can do and how we implement it.
Note that that Linux Kernel lacks floating-point support, i.e., all the math must be implemented using integers. Also files, signals or security descriptors are not available.
Through the rest of the document and your implementation you will learn some of the basic mechanisms, structures and designs common to many areas of Linux Kernel Development. Please consult the recommended links and tutorials in the References Section of this document as those documents detail everything that you need to implement this MP.
TA Introduction
Developmental Setup
In this assignment, you will again work on the provided Virtual Machine and you will develop kernel modules for the Linux Kernel 4.4.0-NetId that you installed on your machine as part of MP0. Again, you will have full access and control of your Virtual Machine, you will be able to turn it on, and off using the VMWare vSphere Console. Inside your Virtual Machine you are free to install any editor or software like Gedit, Emacs and Vim.
During the completion of this and other MPs, errors in your kernel modules could potentially lead to “bricking” your VM, rendering it unusable. If this happens, please post to Campuswire asking for help and a TA will work with Engr-IT to have your VM restored. However, this will cost you precious hours of development time! Fortunately, these problems can be almost entirely avoided by taking the following precautions:
- VM Snapshots: Before installing kernel module, be sure to use the vSphere console to take a snapshot of your VM. If the VM becomes unusable, you can go back to vSphere and restore from this snapshot. A note on snapshots – snapshots are NOT backups, and can go to unbounded sizes as you continue to use your VM. Use snapshots sparingly and delete all of your snapshots at the conclusion of each assignment.
- Code Versioning: If your VM does become unusable, it is possible that Engr-IT will need to reimage your machine, causing you to loose any work stored on it. It is strongly recommended that you prevent loss of work by committing to your course git often. We will only use your last submission before the deadline for grading.
- Don’t DoS
/var/log: During the course of our MPs we will be generating a lot of log messages, which eventually find their way to the/var/logdirectory on our disk. The /var partition on our VM contains about 4GB of space, and if it fills up then certain applications (e.g.,ssh) may stop working. Keep an eye on the/varpartition using thedf -hcommand and remove large log files if it starts getting too full. Another workaround is to symlink/var/logto your main partition as follows:
mkdir /srv/log
rsync -auv /var/log/ /srv/log/
rm -rf /var/log
ln -s /srv/log /var/log
reboot
This will increase the space available to /var/log, but it is still possible to fill up the available space if you get caught in an infinite logging loop, etc., so keep an eye on this regardless.
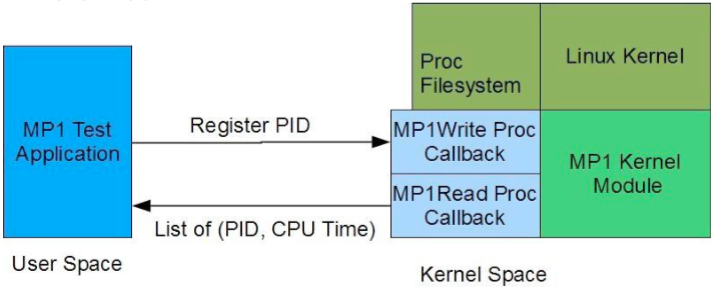
Figure 1: Proc Filesystem Interface between Test Application and MP1 Kernel Module
Starter Code
We have provided some starter code to get started on this MP. You will receive this code in your CS 423 github.
- Create your CS 423 github by following our “Setting up git” guide here
- Once you have your github setup, run the following commands for your cs423/netid/ directory:
git fetch release
git merge release/mp1 -m "Merging initial files"
Problem Description
In this MP you will build a kernel module that measures the Userspace CPU Time of processes registered within the kernel module and a simple test case application that requests this service. In a real scenario many applications might be using this functionality implemented by our new kernel module and therefore our module is designed to support multiple applications/processes to register simultaneously.
The kernel module will allow processes to register themselves through the Proc Filesystem. For each registered process, the kernel module should write to an entry in the Proc Filesystem, the application’s Userspace CPU Time (known also as user time). The kernel module must keep these values in memory for each registered process and update them every 5 seconds. Figure 1 shows the application interface with the kernel module using the Proc filesystem.
The registration process must be implemented as follows: At the initialization of your kernel module, it must create a directory entry within the Proc filesystem (e.g. /proc/mp1). Inside this directory your kernel module must create a file entry (e.g. /proc/mp1/status), readable and writable by anyone (mask 0666). Upon start of a process (e.g. our test application), it will register itself by writing its PID to this entry that you created. When a process reads from this entry, the kernel module must print a list of all the registered PIDs in the system and its corresponding Userspace CPU Times. An example of the format your proc filesystem entry can use to print this list is as follows:
PID1: CPU Time of PID1
PID2: CPU Time of PID2
Your kernel module implementation must store the PIDs and the CPU Time values of each process in a Linked List using the implementation provided by the Linux kernel. Part of the goals of this MP is that you learn to use this facility provided by the kernel. Additionally, the CPU Time values of each process must be periodically updated by using a Kernel Timer. However, you must use a technique called Two-Halves approach. In this approach an interrupt is divided in two parts: Interrupt Handler (Top-Half) and Thread performing the work (Bottom-Half). The slides on Linux Kernel Programming, posted on compass explain this concept more in detail.
In our case the Top-Half will be the Timer Interrupt Handler Its sole purpose will be to wake up the Bottom-Half. For the Bottom-Half we will use a work function in a workqueue. A workqueue is a kernel mechanism that allows you to schedule the execution of a function (work function) at a later time. A worker thread managed by the kernel is responsible of the execution of each of the work functions scheduled in the workqueue. In our MP, the work function will traverse the link list and update the CPU Time values of each registered process.
It is acceptable for your work function to be scheduled even if there are no registered processes. However you might consider an implementation where the timer is not scheduled if there are no registered processes. Figure 2 shows the architecture of the kernel module you should implement, including the timer interrupt and the workqueue.
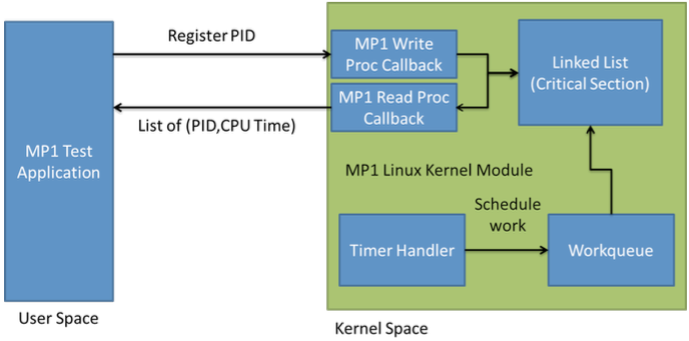
Figure 2: MP1 Architecture Overview
Finally, the kernel module will be responsible of freeing any resource that it allocated during its execution. This includes stopping any work function pending, destroying any timer, workqueue or Proc filesystem entry created and freeing any allocated memory.
As a test case you must implement a simple program that registers itself in the kernel module using the proc filesystem and then calculates a series of factorial computations. This computation can repeat or can be different. However, this program should run for sufficient time to test your kernel module, sometime between 10 and 15 seconds should be sufficient. At the end of the computation the application must read the proc file system entry containing the list of all the registered applications and its corresponding CPU Times.
Implementation Challenges
In this MP you will find many challenges commonly found in Kernel Programming. Some of these challenges are discussed below:
- During the registration process you will need to access data from userspace. Kernel and Applications both run in two separate memory spaces, so de-referencing pointers containing data from userspace is not possible. Instead you must use the function
copy_from_user()to copy the data into a buffer located in kernel memory. Similarly, when returning data through a pointer we must copy the data from kernelspace into userspace using the functioncopy_to_user(). Common cases where this might appear are in Proc filesystem callbacks and system calls. - Another important challenge is the lack of libraries, instead the kernel provides similar versions of commonly used functions found in libraries. For example,
malloc()is replaced withkmalloc(),printf()is replaced byprintk(). Some other handy functions implemented in the kernel aresprintf()andsscanf(). This functions are introduced in [2]. - Throughout your implementation, you will need to face different running contexts. A context is the entity whom the kernel is running code on behalf of. In the Linux kernel you will find 3 different contexts:
- Kernel Context: Runs on behalf of the kernel itself. Example: Kernel Threads and workqueues
- ProcessContext: Runs on behalf of some process. Example: SystemCalls
- InterruptContext: Runs on behalf of an interrupt. Example: TimerInterrupt
- The Linux kernel is a preemptible kernel. This means that all the contexts run concurrently and can be interrupted from its execution at any time. You will need to protect your data structures through the use of appropriate locks and prevent race conditions wherever they appear. Please note that architectural reasons limit which type of locks can be used for each context. For example, interrupt context code cannot sleep and therefore semaphores will create a deadlock when used in this case.
This sleeping restriction in interrupt context also prevents you from using various functions that sleep during its execution. Many of these functions involve complicated operations that require access to devices like printk(), functions that schedule processes, copy data from and to userspace, and functions that allocate memory (e.g kmalloc()). Some exceptions to this rule of thumb are the function wake_up_process() and the function kmalloc() when used with special flags.
Due to all these challenges, we recommend you that you test your code often and build in small increments. You can use the BUG_ON() macro to spot inconsistencies and trigger a stack dump.
Implementation Overview
In this section we will briefly guide you through the implementation. Figure 2 shows the architecture of MP1, showing the kernel module with its workqueue and timer and also the proc filesystem all in kernelspace. In userspace you can see the test application that you will also implement.
Step 1: The best way to start is by implementing an empty (‘Hello, World!’) Linux Kernel Module.
Step 2: After this you should implement the Proc Filesystem entries (i.e /proc/mp1/ and /proc/mp1/status). Make sure that you implement the creation of these entries in your module init function and the destruction in your module exit function.
At this point you should probably test your code. Compile the module and load it in memory using insmod or modprobe. You should be able to see the proc filesystem entries you created using ls. Now remove the module using rmmod or modprobe -r and check that the entries are properly removed.
Step 3: The next step should be to implement the full registration; you will need to declare and initialize a Linux kernel linked list. The kernel provides macros and functions to traverse the list, and insert and delete elements.
Step 4: You will also need to implement the callback functions for read and write in the entry of the proc filesystem you created. Keep the format of the registration string simple. We suggest that a userspace application should be able to register itself by simply writing the PID to the proc filesystem entry you created (e.g /proc/mp1/status). The callback functions will read and write data from and to userspace so you need to use copy_from_user() and copy_to_user(). To keep things simple, do not worry about adding support for page breaks in the reading callback.
Step 5: At this point you should be able to write a simple userspace application that registers itself in the module. Your test application can use the function getpid() to obtain its PID. You can open and write to the proc filesystem entry using fopen() and fprintf(), or you can use sprintf() and the system() function to execute the string echo <pid> > /proc/mp1/status in a privileged shell.
Step 6: The next step should be to create a Linux Kernel Timer that wakes up every 5 seconds. Timers in the kernel are single shot (i.e not periodic). Expiration times for Timers in Linux are expressed in jiffies and they refer to an absolute time since boot. Jiffy is a unit of time that expresses the number of clock ticks of the system timer in Linux. The conversion between seconds and jiffies is system-dependent and can be done using the constant HZ. The global variable jiffies can be used to retrieve the current time elapsed since boot expressed in jiffies.
Step 7: Next you will need to implement the work function. At the timer expiration, the timer handler must use the workqueue API to schedule the work function to be executed as soon as possible. To test your code, you can use printk() to print to the console every time the work function is executed by the workqueue worker thread. You can see these messages by using the command dmesg in the command line. Also, please note that the workqueue API was updated for kernel 2.6.20 and newer, therefore some documentation about workqueues on the internet might be outdated.
Step 8: Now, you will need to implement the updates to the CPU Times for the processes in the Linked List. We have provided in the file mp1_given.h a helper function int get_cpu_use(int pid, unsigned long *cpu_value) to simplify this part. This function returns 0 if the value was successfully obtained and returned through the parameter cpu_value, otherwise it returns -1. As part of the update process, you will need to use locks to protect the Linked List and any other shared variables accessed by the three contexts (kernel, process, interrupt context). The advantage of using a two half approach is that in most cases the locking will be placed in the work function and not in the timer interrupt. If a registered process terminates, get_cpu_use will return -1. In this case, the registered process should be removed from the linked list.
Step 9: Finally you should check for memory leaks and make sure that everything is properly deallocated before we exit the module. Please keep in mind that need to stop any asynchronous entity running (e.g timers, thread, workqueues) before deallocating memory structures. At this time, kernel module coding is finished. Now you should be able to implement the factorial test application and have some additional testing of your code.
Grading Criteria
Submission
To submit your code, ensure you have done both of the following:
- Turn your code in via git by committing it you course repo. You can do this via the following commands:
git add -A
git commit -m "MP submission"
git push origin master
- Ensure your module is actively loaded on your VM.
Adding a Tag
We will grade your latest pre-deadline commit for each checkpoint and the final MP. However, if you want us to grade a specific commit, you can tag it with a specific tag. Assuming that your tagged commit is before the deadline, we will grade your tagged commit instead of your latest pre-deadline commit. This will allow you to continue to work on your MP after ensuring you have made your submission for the checkpoint.
The tag names to use are as follows:
- For Checkpoint #1:
mp1-cp1 - For Checkpoint #2:
mp1-cp2 - For the final submission:
mp1-final
(If you do not have a tag with the name, we will grade your latest pre-deadline commit+push. It’s not necessary to add the tag, but it may give you extra assurance. :))
Grading Criteria
| Criterion |
|---|
| Can we insert your module? |
| Does your user app function correctly? |
| Does proc read work correctly? |
| Does proc write work correctly? |
| Does the interrupt handler work correctly (incl. removing finished processes)? |
| Does your module correctly support multiple processes? |
| Is your critical region lock correctly implemented? |
| Does your module correctly free all memory? |
| Can we remove your module (rmmod)? |
| Documented code and README file |
| Your code compiles and runs correctly and does not use any Floating Point arithmetic. |
| Your code is well commented, readable and follows software engineering principles. |
References
- The Kernel Newbie Corner: Kernel Debugging Using proc “Sequence” Files http://www.linux.com/training-tutorials/kernel-newbie-corner-kernel-debugging-using-proc-sequence-files-part-1/ http://www.linux.com/training-tutorials/kernel-newbie-corner-kernel-debugging-proc-sequence-files-part-2/ http://www.linux.com/training-tutorials/kernel-newbie-corner-kernel-debugging-proc-sequence-files-part-3/
- The Linux Kernel Module Programming Guide (a little outdated, but still useful) http://tldp.org/LDP/lkmpg/2.6/html/index.html
- Linux Kernel Linked List Explained https://rootfriend.tistory.com/entry/Linux-Kernel-Linked-List-Explained
- Kernel API’s Part 3: Timers and lists in the 2.6 kernel https://developer.ibm.com/technologies/linux/tutorials/l-timers-list/
- Access the Linux Kernel using the Proc Filesystem, (a little outdated, still useful) https://developer.ibm.com/technologies/linux/articles/l-proc/
- Kernel APIs Part2: Deferrable functions, kernel tasklets, and work queues https://developer.ibm.com/technologies/linux/tutorials/l-tasklets/
- Love Robert, Linux Kernel Development, Chapters 6, 8-11, 17-18, Addison-Wesley Professional, Third Edition
- Linux synchronization methods (2.6 kernel) - Links Deprecated