
The main purpose of this assignment is to (a) give you experience building and using the simulator software and (b) to get you thinking about architecture quantitatively.
The following figure describes the data cache system for a particular microprocessor. We know that the processor consists of a simple in-order pipeline that blocks on L1 cache misses. We know very little about the caches of this system except that the L1 cache, if it is associative, uses the Least Recently Used (LRU) replacement policy. We also know that the latency between the L1 and L2 cache is p cycles.
In order to discover the size and organization of the L1 data cache, we have decided to run a small code kernel on it, which is described in pseudo code below. The code sequentially accesses D elements of an array called A repeatedly 100 times.
do 100 times {
for i = 0 to D-1 {
access A[i];
}
}
By running this small loop for various values of D, we are able to obtain a graph of the average latency for an access to the array A. The graph is shown below.
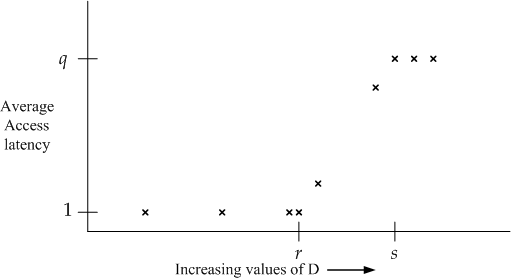
Using the values q, r, and s derived from this graph, along with p (L2 cache latency), determine the following properties of the L1 cache: (a) hit latency, (b) size, (c) line size, (d) associativity.
What (if anything) do you learn by running the loop from Problem 1 on your laptop (or any other computer to which you have access)? Explain.
In class on Wednesday Aug 23 we discussed the performance improvements that one gets from faster transistors versus the performance improvements that come from architectural improvements. I showed you a graph and claimed that it demonstrated that of the ~72x performance improvement in Pentium processors over the last 10 years, 8x came from faster transistors and 9x came from "architecture."
The question then came up, "of the 9x performance improvement from architecture, how much (if any) was due to `easy' architecture (just making the caches bigger)?" My assertion was that average memory latency has been increasing for the last 10 years, relative to the rest of the processor, even though caches are getting much larger. This is because, while logic transistors have sped up by a factor of about 8, DRAM speeds have increased by only about a factor of 2. Thus a DRAM access today takes about 4 times more gate delays today than it did in 1994.
Let's test my assertion. After you unpack, build and run the simulator (instructions below), use the command line parameters to model memory systems similar to those seen in 1994 and in 2004. Currently the simulator pipeline has a structure somewhat similar to a circa 1994 Pentium: two way inorder with simple branch prediction.
You should model two memory systems. For 1994 era memory assume 16K L1 I and D caches, no L2 cache, and DRAM access cost of 30 cycles. For a 2004 era memory system model an L2 cache and a DRAM access cost of 120 cycles (similar to assuming that we took a c. 1994 pentium netlist added an L2 cache to take advantage of our larger transistor budget and fabbed it on a state-of-the-art 2004 fab). You'll have to make some assumptions about L2 hit latency. One reasonable assumption is that SRAM latency is sqrt(size/16384). Thus a 64K L2 would have a 2 cycle latency, 256K => 4 cycles, 1M => 8 cycles, 4M => 16 cycles, 16M => 32 cycles.
What happens as you change your data cache orgranization? Does the number of cycles to execute the program increase or decrease, and by how much?
Recal that the formula for average memory latency is:
h lh + (1 - h) lm
where h is hit-rate, lh is hit latency, and lm is miss latency. What hit rate would you need to achieve to completely make up for the relative increase in DRAM latency?
You may work alone or in groups of 2. In previous years I have observed that people working in groups of 2 got the most out of the assignments (and the course). Each group should turn in a short (1-2 pages for assignment 1) report on what you implemented and what you learned. You should address questions like the following: What assumptions did you make? What did you try that didn't work? Which of the changes you made were most and least effective? For those features that weren't very effective, why do you think they didn't work very well?
The simulator is guaranteed to work only on Linux machines. It has been tested on EWS Linux Lab machines in Everitt & Engineering Hall, and on RedHat Linux 9.0 and Fedora Core 3
Download the tarball for the simulator: ece511-sim.tar.gz (link fixed at 1830hrs on Friday Sep. 1st)
Unzip and untar the simulator by running the command:
This will create a source directory named "ece511-sim". The source directory has the following structure:
+--- ece511-sim +---- apps +-------- lzw (spec benchmark)
| +-------- gcc (spec benchmark)
| +-------- etc.
|
+---- Makefile
+---- pipelined-model.cc
+---- etc.
Run make in the ece511-sim directory:
This compiles the simulator
Compile and run a program on the simulator:
(lzw is a version of the unix compress program. It creates a buffer of random text, then compresses and decompresses the text). While it is running it prints out the random text and then some statistics:
The compressed/uncompressed size is: 802 Files both have length 802 Characters match. processor halted Number of cycles run: 2859871 Number of instructions: 952102 utilization: 0.332918 doubled clock gives equivalent speed to single-pump IPC of 0.665836 cache hits: 196000, cache misses: 22214 branches: 103858, mispredicted 7390 mispredictiction rate: 0.071155
Make changes to the simulator. The simulator code is in the directory ece511-sim. For the first assignment you will mainly be modifying the various cache parameters. To rebuild the simulator go to the directory ece511-sim and type make.