Lab 6
In this machine problem, you will get familiar with face modeling and animation techniques, learn to use ANNs (artificial neural networks) to map features of speech signals to facial animation parameters, and produce facial animation sequences from the audio tracks.
Useful Files
- Code, test code, data, and solutions.
- Images of the solutions, created using visualize.py.
- Videos of the solutions, created using visualize.py.
- Autograder submission site.
- MP 6 Walkthrough.
The Audio-Visual Database
The pre-processed directory data contains the following data files:
- train_audio.txt and train_video.txt
Audio-visual data for training the ANN. It has the following elements:
- train_audio.txt is a matrix of the audio features. The kth frame of the audio feature matrix can be accessed as self.train_audio[k , :]. It represents the audio feature vector of the frame k of the audio.
- train_video.txt is a matrix of the visual features. The kth frame of the visual feature matrix can be accessed as train_video[k,:]. It represents the visual feature vector of the frame k of the video. A visual feature vector contains three numbers. The first one is the Δ width of lips (Δw=w-w0). The last two numbers are the Δ height of the upper lip (Δh1=h1-h10), and the Δ height of the lower lip (Δh2=h2-h20) where w0, h10, h20 are the width and heights of the neutral lips (see Figure 1).
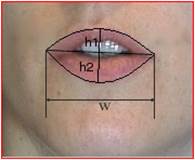
Figure 1. The visual features.
- validate_audio[0-9].txt and validate_video[0-9].txt
audio-visual data for validation of the ANN. You will use these data to compute the gradient of the neural network weights with respect to error.
- validate_audio[0-9].txt are the audio feature validation matrices. Each frame validate_audio[k,:] represents the audio feature vector of frame k.
- validate_video[0-9].txt are the visual feature matrices. Each frame validate_video[k,:] represents the visual feature vector of frame k.
- test_audio[0-9].txt
test_audio[0-9].txt are the test audio data matrices. Each row is an audio feature vector. These files contain the MFCC feature vectors corresponding to the waveforms test[0-9].wav. The waveforms are only used at the end, if you want to add audio to the video files that you create.
- silence_model.txt
silence_model.txt will be used to decide if an audio frame corresponds to silence.
Data for Producing Animation
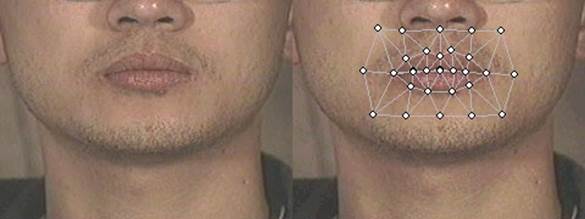
Figure 2: Mouth image (left); Mouth image with triangular mesh (right)
In this machine problem, facial animation is achieved by image warping. Two files are provided for image warping. In addition, a waveform file is provided as the sound track corresponding to testAudio for making the final movie file.
- refimage.jpg
A neutral mouth image will be provided (see Figure 2). You will use it to generate a mouth animation image sequence.
- reftriangles.txt and refpoints.txt
A triangular mesh that triangulates the mouth area in mouth.jpg (see Figure 2). You will use this mesh and the mouth image to generate new mouth images through image warping. The format of the files are:
- refpoints.txt
- x coordinate of point 1, y coordinate of point 1
- x coordinate of point 2, y coordinate of point 2
- ...
- reftriangles.txt
- vertex 1, vertex 2, vertex 3 (of the 1st triangle)
- ...
- test.wav
The waveform file corresponding to the audio feature matrix test_audio.txt.
Tasks
The provided code (the __init__ function for the submitted.Dataset object) loads pre-processed neural network weights from weights1.txt, bias1.txt, weights2.txt, bias2.txt, and loads neural network validation and test data from from validate_audio(testcase).txt, validate_video(testcase).txt, and test_audio(testcase).txt, where (testcase) is replaced by one of the digits 0-9. Once these files have been loaded for you, and the attributes of the dataset have been initialized, you should write code to do the following things:
- Use the validation data set to compute the error of the NN (forward propagation), and to compute the gradient that would be used to re-train the neural network mapping from audio features to visual features (back-propagation).
- Compute forward propagation also for the test data. Since there are no video features for the test data, you can't know what the error is, so you can't do back-propagation.
- Write your image warping code in python. The code takes the visual features as input and synthesizes new mouth images.
- Apply the mapping to the test audio features and obtain synthetic visual features.
- Produce image sequence for the synthesized visual features.
- The file visualize.py will use OpenCV to write out your video file for you. If you have ffmpeg installed on your computer, it will then add the audio to the video file, so you can watch the video, to see if the result is reasonable. This is usually the best way to debug your results -- run visualize.py, then look in the directory vis for files like testcase0_audiovisual.avi, and try playing them to see if it looks reasonable.
Detailed Description
- Image warping: First, you need to deform the mesh according to the visual features. The deformation of the mesh can be decided by interpolation from the visual features. In the file submitted.py that you will submit, a python function “interpolate_vfeats” using linear interpolation will be provided. Then write a warping function to generate the deformed mouth images using the given mouth image (See Figure 2). For the pixels outside the mesh, leave them unchanged from the reference image. For the pixels in the holes inside lips, leave them black.
- Load pre-processed data.
- ANNs training and testing:
- You will write the functions submitted.Dataset(testcase).set_layer1validate(), submitted.Dataset(testcase).set_layer1test(), submitted.Dataset(testcase).set_layer2validate(), and submitted.Dataset(testcase).set_layer2test(). These functions compute the forward-propagation of the multilayer perceptron for both validation and test data.
- You will write the functions submitted.Dataset(testcase).set_grad2() and submitted.Dataset(testcase).set_grad1(). These compute the back-propration of the multilayer perceptron for the validation data. These gradients could be used to train the neural network.
- Use the estimated visual feature from test data, the triangular mesh, and the mouth image to generate mouth image sequences.
- Produce an animation movie file.
- Firstly generate face images from visual features.
- Save the images in the numpy array self.intensities.
- Use the provided function visualize.py to convert the image sequence into a movie file.
What to submit:
The file submitted.py, containing all of the functions that you have written.