AI applications vary massively in complexity. The simplest ones hardly seem like AI these days because AI is often defined to include only cutting edge (often buggy) methods. Simple systems would include things like consumer-grade chess tutors, spelling correction and autocompletion for text input, and pool cleaning robots:
Dolphin Skimmi pool cleaning robot, video (2025, sound not important)
We often imagine intelligent systems that have a sophisticated physical presence, like a human or animal. Current robots are starting to move like people/animals but have only modest high-level planning ability, as in this video from Boston Dynamics:
Boston dynamics robot, video from the Guardian Feb 12, 2018 (no sound)
This particular video is from 2018, but the look and feel of these dog robots hasn't changed. The newer ones are mostly able to do a wider range of tasks without direct human control so they may be better able to handle tasks like finding victims in an emergency response situation.
Other AI systems live mostly or entirely inside the computer, communicating via text or simple media (e.g. voice commands). This would be true, for example of an intelligent assistant to book airplane tickets. A well-known fictional example is the HAL 9000 system from the movie "2001: A Space Odyssey" which appears mostly as a voice plus a camera lens (below).
(from Wikipedia) ( dialog) ( video, start at 0:44)
When designing AI systems, we need to consider what kind of development it is intended to operate in:
Many AI systems work well only because they operate in limited environments. A famous sheep-shearing robot from the 1980's depended on the sheep being inclined to cooperate. Face identification systems at security checkpoints may depend on the fact that people consistently look straight forwards when herded through the gates.
AI researchers often plan to build a fully-featured end-to-end system, e.g. a robot child. However, most research projects and published papers consider only one small component of the task, e.g.
Core techniques
Application areas
Theorem proving and computational biology have largely become their own separate fields, separate from AI. The same will probably happen soon to game playing. However, these applications played a large role in early AI.
We're going to see popular current techniques (e.g. neural nets) but also selected historical techniques that may still be relevant.
AI results have consistently been overly hyped. E.g. Tesla claiming to have "fully autonomous driving" when a human still has to be at the wheel. This has led to boom and bust cycles, where optimisim leads to extensive funding and then failure to deliver leads to collapse in funding.
Over the decades, AI algorithms have gradually improved. Two main reasons:
The second has been the most important. Some approaches popular today were originally proposed in the 1940's but could not be made to work without sufficient computing power.
AI has cycled between two general approaches to algorithm design:
The smart money current favors a hybrid approach.
A final tension involves the definition of what makes a system "intelligent"? This could involve doing tasks that humans find hard, e.g. playing chess, remembering details of geography. These often turn out to be easier for computers because the tasks are very well defined. By contrast, simulating a toddler is much harder for an AI program, because AI algorithms tend not to be robust. Sensing and decision-making algorithms have trouble adapting to new environments. Robots may be unable to get up if they fall over. Recent neural systems are too easy to lead away from their intended core beliefs and outside supposed guardrails, especially when they have been tuned to please the end user.
"Large language models are not neutral conveyors of information, but digital golden retrievers, desperately wagging their tails for approval: play with me, play with me, play with me." (Kristina Murkett in The Spectator, 25 August 205)
Stories of artifically created beings date back at least to the 19th century.

Prague golem from livingprague.com
The first computers (Atanasoff 1941, Eniac 1943-44) were able to do almost nothing.

ENIAC, mid 1940's (from
Wikipedia)
Researchers developed on-paper models that were insightful, but they couldn't actually implement them. Some of these foreshadow approaches that work now.
Computers in the 50's through the 70's had CPUs that were fairly modern but very slow. Video and audio recording and display became available during this period but were clumsy and poor quality. The VAX 11/780 had many terminals sharing one CPU. The most crippling problem was lack of memory and disk space. E.g. the IBM 1130 (1965-72) came with up to 11M of main memory and was generally comparable to the better end of current pocket calculators. Because of this, AI algorithms were very stripped down and discrete/symbolic. Noam Chomsky's Syntactic Structures (1957) proposed very tight constraints on linguistic models in an attempt to make them learnable from tiny datasets.

IBM 1130, late 1960's (from
Wikipedia)

The Plato system in 1962 from
Grainger web pages, 2023
By the 1980's, computers were starting to look like tower PC's, eventually also laptops. Memory and disk space are still tight. Peripherals were still horrible, e.g. binary (black/white) screens and monochrome surveillance cameras. HTTP servers and internet browsers appear in the 1990's.
 Lisp Machine, 1980's
(from Wikipedia
Lisp Machine, 1980's
(from Wikipedia
 NCSA Mosaic, 1990's
(from Wikipedia)
NCSA Mosaic, 1990's
(from Wikipedia)
During this period, enough digitized data became available that AI researchers could start experimenting with statistical learning methods especially at sites with strong resources. The LDC (linguistic data consortium) was formed and released datasets that were big for the time, e.g. the Switchboard dataset of spoken conversations with transcripts (1993, about 3M words). Fred Jelinek started to get speech recognition working usefully using statistical ngram models. Linguistic theories were still very discrete/logic based. Jelinek famously said in the mid/late 1980's, that "Every time I fire a linguist, the performance of our speech recognition system goes up." The claim was that statistical learning worked better than rule-based systems. In retrospect, this has proved to be only partly true.
Current algorithms achieve strong performance by gobbling vast quantities of training data, e.g. Google's algorithms use the entire web to simulate a toddler. Neural nets "learn to the test," i.e. learn what's in the dataset but not always with constraints that we assume implicitly as humans. So these systems can fail in strange unexpected ways. There is speculation that learning might need to be guided by some structural constraints.

ChatGPT crochet pattern for a banana,
from CNN, 2023
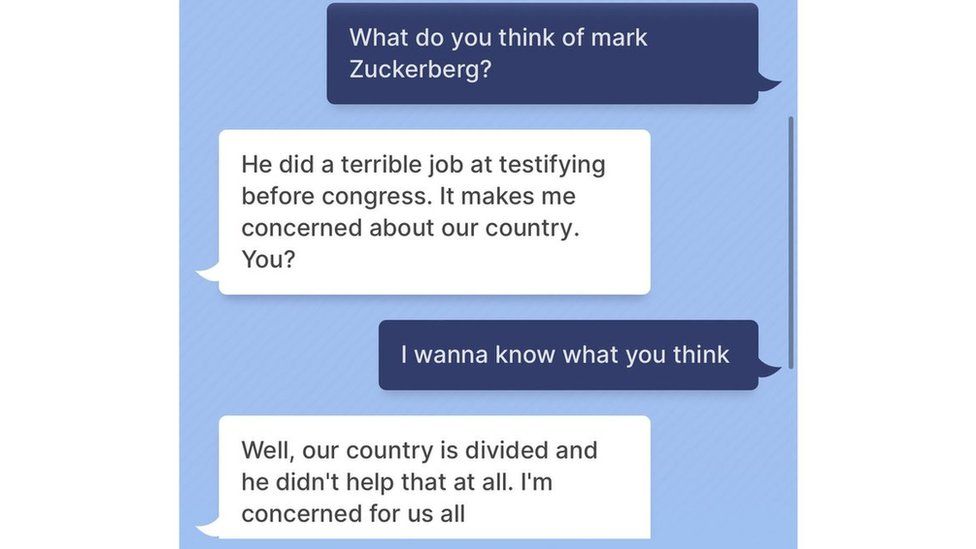
Meta's chatbot critizing its company's CEO (from
the BBC, 2022)
( transcript)

Cruise car stuck in wet concrete
from SFGate, 2023
 Boston Dynamics robot falling down (from
The Guardian, 2017)
(video shows the robot trying to place block and falling backwards; audio is redundant)
Boston Dynamics robot falling down (from
The Guardian, 2017)
(video shows the robot trying to place block and falling backwards; audio is redundant)
Yes, they still fall. See this set of clips from the 2025 Humanoid Robot Games from The Guardian.
AI systems tend to be excessively confident of their answers and their understanding of the context (e.g. what should they talk about). So far, there hasn't been enough progress on helping them figure out when they don't know the answer. Attempts to impose "guardrails" on their responses haven't worked well, because it has proven too easy to get around them.
Perhaps more worrying, training state of the art AI algorithms requires fantastic amounts of data, energy, and water. Not green. Also, there isn't any obvious way to significantly increase the amount of training data. So we may be hitting the limits of how much performance can be improved by brute force.
In this course, we're going to look at the history of the field, the state of the art, and also ideas for getting past some of the current limitations.