
| |
CS440/ECE448 Fall 2025MP 7: HMM Spelling CorrectionDue date: Friday October 31st, 11:59pm |
For this MP, you will implement spelling correction using an HMM model. Make sure you understand the algorithm before you start writing code, e.g. look at the lectures on Hidden Markov Models and Sections 17.1, 17.2, and 17.4 of Jurafsky and Martin.
Basic instructions are the same as in previous MPs:
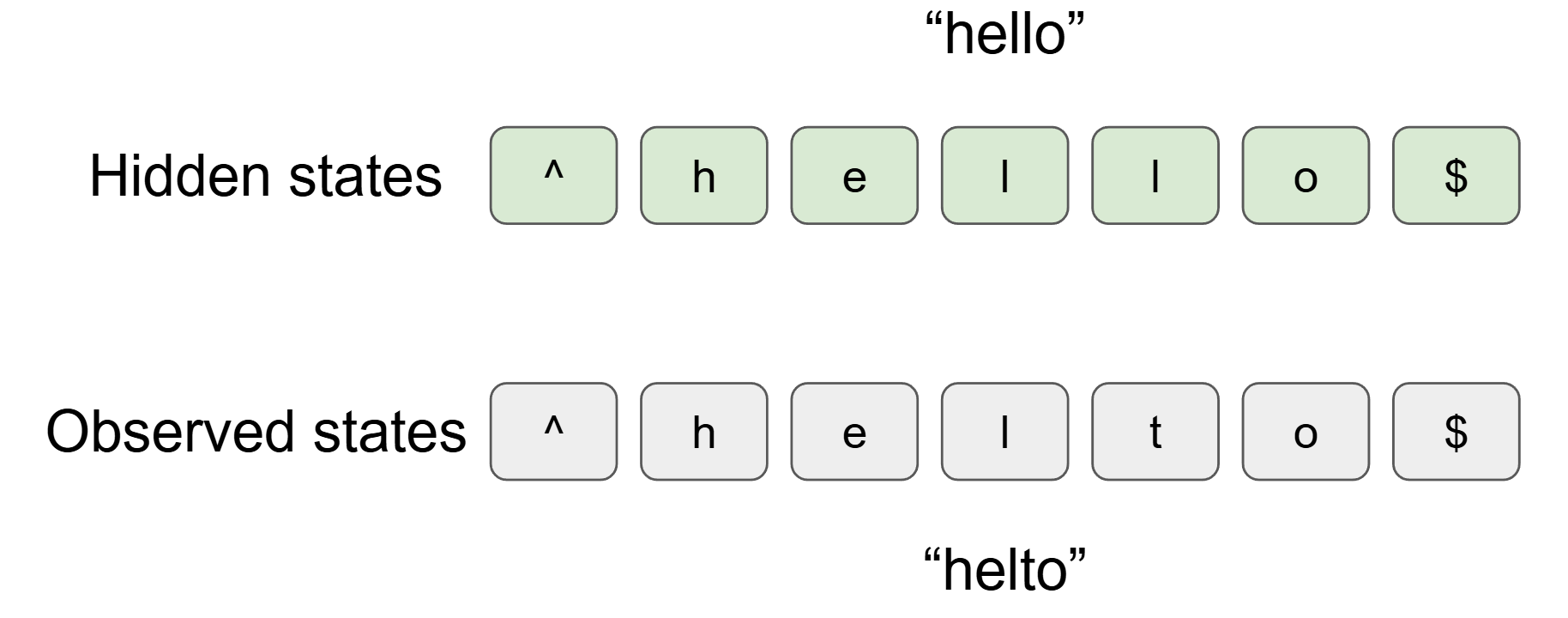
In this MP, you will implement a simplified spelling correction system. For instance, if you type "intellifence", it is likely that you originally meant "intelligence".
Spelling correction, when not considering character insertions or deletions,
can be viewed as a sequence labeling problem.
The observed sequence is the sequence of characters in the (possibly)
misspelled word ("intellifence"), and the hidden sequence is the sequence
of characters in the correctly spelled word. Your goal is to find the most
likely sequence of hidden characters given the observed characters, which
can be done using the Viterbi algorithm learned from the class.
The provided script for MP7 (mp7.py) reads data from two files (--train and --test). Your viterbi_1() function (in viterbi.py) will be given these data, where it calls the training() function to compute the parameters of your HMM from the training data. It will run the Viterbi algorithm on the test data and return the predicted correct spellings. Note: You are REQUIRED to implement the `viterbi_stepforward()` function, which computes a single column of the Viterbi trellis. This function will be called by your `viterbi_1()` function. We will test the `viterbi_stepforward()` function separately.
The provided script will compute the character error rate (CER) against the ground-truth answer and your HMM's predictions. CER is the sum of inserted, deleted, and substituted characters there are in a word divided by the number of characters in the word, where the lower is better. The autograder will show your CER and the passing threshold for each test case.
You will need to fill in the three functions in viterbi_1.py:
The code package (and data) for the MP (template.zip) contains these code files:
The code package contains the following training and development data:
We provide a small example that will be useful for debugging viterbi_1.py in test_viterbi and test_data/test.txt. More details about this example will be provided below (see this section of the instructions) and we strongly recommend you use it.
You should use the provided training data to train the parameters of your model and the development sets to test its accuracy.
To run the code on the data you need to tell it where the data is:
python3 mp7.py --train data/tiny_typos_train.txt --test data/tiny_typos_test.txt
The program will run the algorithm and report one metric:
You will be submitting one file to Gradescope: viterbi_1.py. Each of these submit points times out after 10 minutes. Bear in mind that your laptop may be faster than the processor on Gradescope.
The Gradescope autograder will run your code on the development dataset from the supplied template and also a separate (unseen) set of data from the same corpus. In addition, your code will be tested on one or more hidden datasets that are not available to you, which may have different set of characters from the ones provided to you.
Do NOT hardcode any of your important computations, such as transition probabilities and emission probabilities, character set, etc.
The following is an example of the set of possible hidden states in your HMM, corresponding to the intended (correct) characters in a word. Remember: you should not hardcode anything about this character set, because we will test your code on other datasets with different alphabets or symbols.
The provided code converts all words to lowercase when it reads in each sentence. It also adds two dummy words at the ends of the sentnce: ^ (START) and $ (END). These tags are just for standardization; they will not be considered in accuracy computations.
Since every word begins with ^, the initial probabilities for your HMM can have a very simple form, but you should not hardcode into your program. Your code also needs to learn the transition probabilities (between correct characters) and the emission probabilities (mapping each correct character to a possibly mistyped observed character). The transitions from ^ encode the likelihood of starting a word with each possible first letter.
Your spelling correction system should implement the HMM trellis (Viterbi) decoding algorithm as seen in lecture or Jurafsky and Martin. That is, the probability of each intended character depends only on the previous intended character, and the probability of each observed character depends only on the corresponding intended characters. This model will need to estimate three sets of probabilities:
It's helpful to think of your processing in five steps:
You'll need to use smoothing to get good performance. Make sure that your code for computing transition and emission probabilities never returns zero. Laplace smoothing is a good choice for a smoothing method.
For example, to smooth the emission probabilities, consider each intended character individually. For some intended character C, you must ensure that \( P_e(O|C) \) is non-zero for any observed character O (including ones never seen with C in training). You can use Laplace smoothing (as in MP1) to fill in a probability for UNSEEN, to use as the shared probability value for all observed characters O that did not appear with C in training. The emission probabilities \( P_e(O \mid C) \) should sum to 1 when C is fixed and we sum over all observed symbols O (including UNSEEN). Mathematically:
\(V_C\) = number of unique observed characters seen in training data for intended character C
\(n_C\) = total number of characters seen in training data for intended character C
\(P_e(\)UNSEEN\(|C)\) = \( \frac {\alpha}{ n_C + \alpha(V_C+1)} \)
\(P_e(O|C)\) = \( \frac {\text{count}(O) + \alpha}{ n_C + \alpha(V_C+1)} \)
This simple version of Viterbi will get around 8.96% CER on simple_typos_val.py and 0% CER on tiny_typos_test.py. You should write this simple version of Viterbi as the viterbi_1 function in viterbi_1.py.
You will continue to improve your Viterbi implementation in MP8.
DO NOT ATTEMPT TO IMPROVE VITERBI 1.
To get through all the parts of the MP, your Viterbi implementation must be computing the trellis values correctly and also producing the output character sequence by backtracing. This is very much like the maze search where you searched forwards to get from the start to the goal, and then traced backwards to generate the best path to return. If you are producing the output sequence as you compute trellis values, you're using an incorrect ("greedy") method.
To help you isolate and debug processing steps 4. and 5. of the Viterbi implementation, we have provided a copy of the small example from Jurafsky and Martin (section 8.4.6). As a reminder, the relevant files are:
viterbi_1(train,test) function
that comes after computing the init_prob, emit_prob, trans_prob).
... but we highly recommend you use it.DO NOT SUBMIT TEST_VITERBI TO GRADESCOPE. THIS IS A DEBUGGING TOOL...
How to use test_viterbi:
python3 test_viterbi.py
Your Output is: ['^hello$']
Expected Output is: ['^hello$']
then you're in good shape. Continue to work on the assignment and
submit your code to Gradescope when you're ready.
When testing on the real dataset, you may find it helpful to use the provided training/validation data. If you look at the emission probabilities or the v array values for a word, the correct character should be one of the top couple values. Obviously unsuitable characters should have much lower values.
You can also print the matrix of transitions. It's not easy to be sure transitions should be highest. However, you can identify some transitions that should have very low values, e.g. transitions from anything to START.
Some additional hints for making your code produce correct answers and run fast enough to complete on the autograder: