Person: PICK UP A BIG RED BLOCK.
Computer: OK. (does it)
Person: GRASP THE PYRAMID.
Computer: I DON'T UNDERSTAND WHICH PYRAMID YOU MEAN.
The area of natural language and speech processing covers algorithms for three types of tasks:
Generation is easier than understanding, but still hard to do well.
Natural language algorithsm divide roughly into four types
Algorithms and systems often handle only part of this process. For example, a speech transcription system puts out written text, but this text might then be read and understood by a human user. Text-only systems omit the lowest level of speech process. A so-called "deep system" includes explicit semantic information, whereas a "shallow system" operates directly on the low-level or mid-level representations, omitting semantics. An "end-to-end" neural net covers several layers of processing using a network that is trained as one unit, though the traditional processing stages are frequently still visible in the net's design and/or what layers end up trained to do.
Interactive systems using natural language have been around since the early days of AI and computer games. For example:
These older systems used simplified text input. The computer's output seems to be sophisticated, but actually involves a limited set of generation rules stringing together canned text. Most of the sophistication is in the backend world model. This enabled the systems to carry on a coherent dialog.
These systems also depend on social engineering: teaching the user what they can and cannot understand. People are very good at adapting to a system with limited, but consistent, linguistic skills.
Deep NLP systems have usually been limited to focused domains, for which we can easily convert text or speech into a representation for underlying meaning. A simple example would when Google returns structured information for a restaurant, e.g. its address and opening hours. In this case, the hard part of the task is extracting the structured information from web pages, because people present this information in many different formats. It's typically much easier to generate natural language text, or even speech, from structured representations.
End-to-end systems have been built for some highly-structured customer service tasks, e.g. speech-based airline reservations (a task that was popular historically in AI) or utility company help lines. Google had a recent demo of a computer assistant making a restaurant reservation by phone. There have also been demo systems for tutoring, e.g. physics.
Many of these systems depend on the fact that people will adapt their language when they know they are talking to a computer. It's often critical that the computer's responses not sound too sophisticated, so that the human doesn't over-estimate its capabilities. (This may have happened to you when attempting a foreign language, if you are good at mimicking pronunciation.) These systems often steer humans towards using certain words. E.g. when the computer suggests several alternatives ("Do you want to report an outage? pay a bill?") the human is likely to use similar words in their reponse.
If the AI system is capable of relatively fluent output (possible in a limited domain), the user may mistakenly assume it understands more than it does. Many of us have had this problem when travelling in a foreign country: a simple question pronounced will may be answered with a flood of fluent language that can't be understood. Designers of AI systems often include cues to make sure humans understand that they're dealing with a computer, so that they will make appropriate allowances for what it's capable of doing.
Modern systems (esp. LLM ones) work confidently and fluently, except when they don't.
Google translate is impressive, but can also fail catastrophically. A classic test is a circular translation: X to Y and then back to X. Google translate sweeps up text from the entire internet but can still be made to fail. It's best to pick somewhat uncommon topics (making kimchi, Brexit) and/or a less-commmon language, so that the translation system can't simply regurgitate memorized chunks of text.
Here's two failures on the same piece of text. The first, using Chinese written in characters, merely mangles the meaning of the sentence. If we extract the pinyin from Google's Chinese output and try to translate that back into English, the result is recognized as Maori and translates to gibberish in English.
A serious issue with current AI systems is that they have no idea when they are confused. A human is more likely to understand that they don't know the answer, and say so rather than bluffing.
Here's a very recent (spring 2023) failure from Google translate, which tripped up a student in CS 340. Here is an extract from the original English project instructions
The xloc and yloc provide the location on the canvas that is your tile. In this case the upper left hand corner of the canvas.
You will return HTTP/455 "Authorization token invalid" if the token does not match your token otherwise HTTP/200 for success.
And here is its Chinese translation. Notice the change in HTTP codes.

Here are two more failures:
The natural language pipeline may start with text but it may start with a raw speech waveform. Here's the raw speech signal for the word "computer". The top line shows the acoustic waveform. The bottom line shows a "spectrogram" in which the input has been transformed to show how much energy is at each frequency. (Frequency is the vertical axis.)
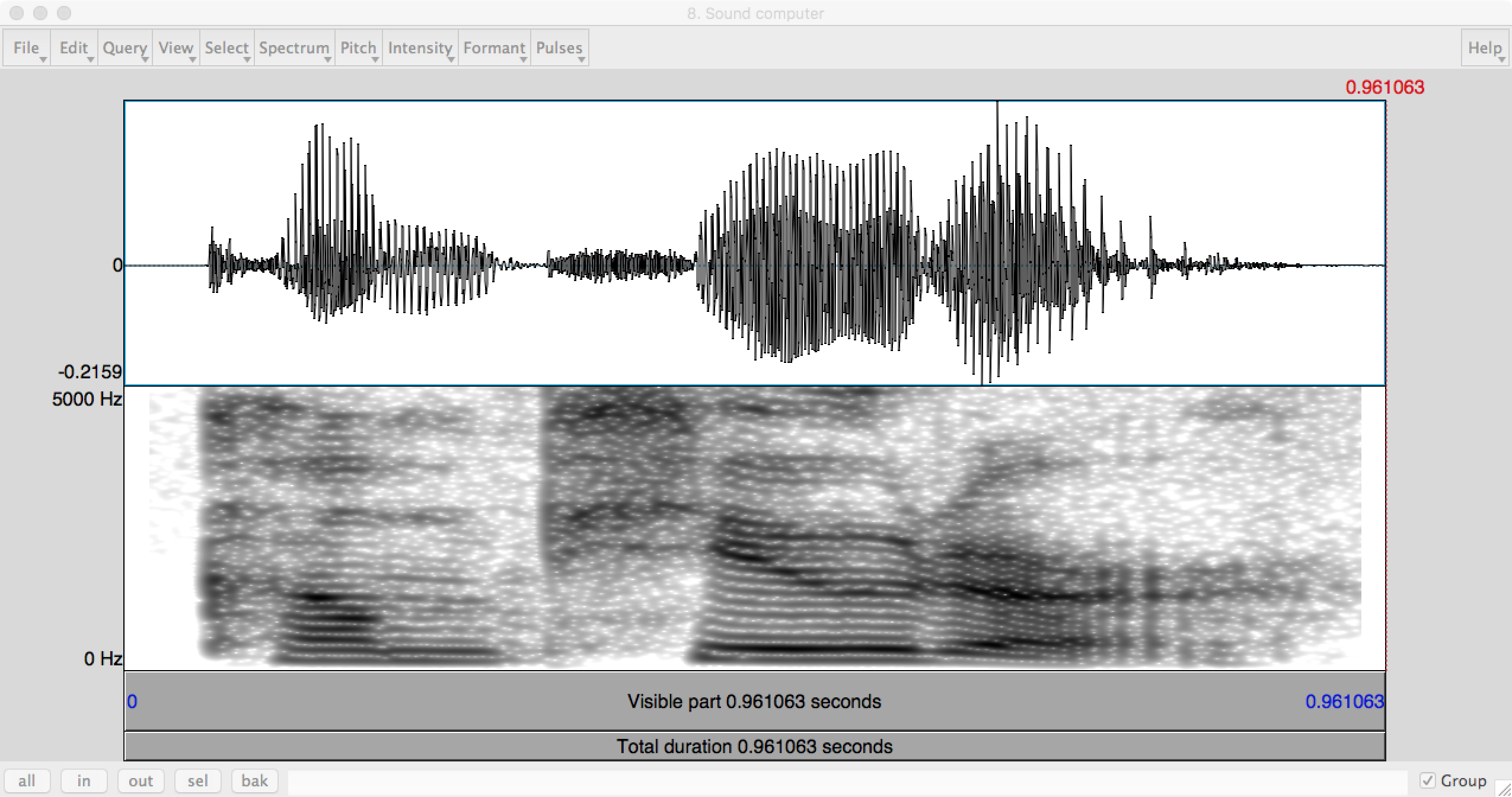
The first "speech recognition" layer of processing turns speech (e.g. the waveform at the top of this page) into a sequence of phones (basic units of sound). We first process the waveform to bring out features important for recognition. The spectogram (bottom part of the figure) shows the energy at each frequency as a function of time, creating a human-friendly picture of the signal. Computer programs use something similar, but further processed into a small set of numerical features.
Each phone shows up in characteristic ways in the spectrogram. Stop consonants (t, p, ...) create a brief silence. Fricatives (e.g. s) have high-frequency random noise. Vowels and semi-vowels (e.g. n, r) have strong bands ("formants") at a small set of frequencies. The location of these bands and their changes over time tell you which vowel or semi-vowel it is.
Recognition is harder than generation. However, generation is not as easy as you might think. Very early speech synthesis (1940's, Haskins Lab) was done by painting pictures of formants onto a sheet of plastic and using a physical transducer called the Pattern Playback to convert them into sounds.
| Pattern Playback (1940's, Haskins Labs) |
|---|
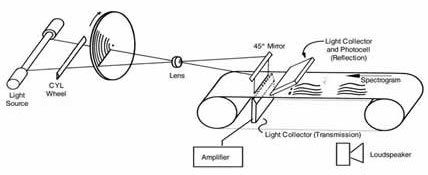
|
Synthesis moved to computers once these became usable. One technique (formant synthesis) reconstructs sounds from formats and/or a model of the vocal tract. Another technique (concatenative synthesis) splices together short samples of actual speech, to form extended utterances.
The voice of Hal singing "Bicycle built for two" in the movie "2001" (1968) was actually a fake, rather than real synthesizer output from the time.
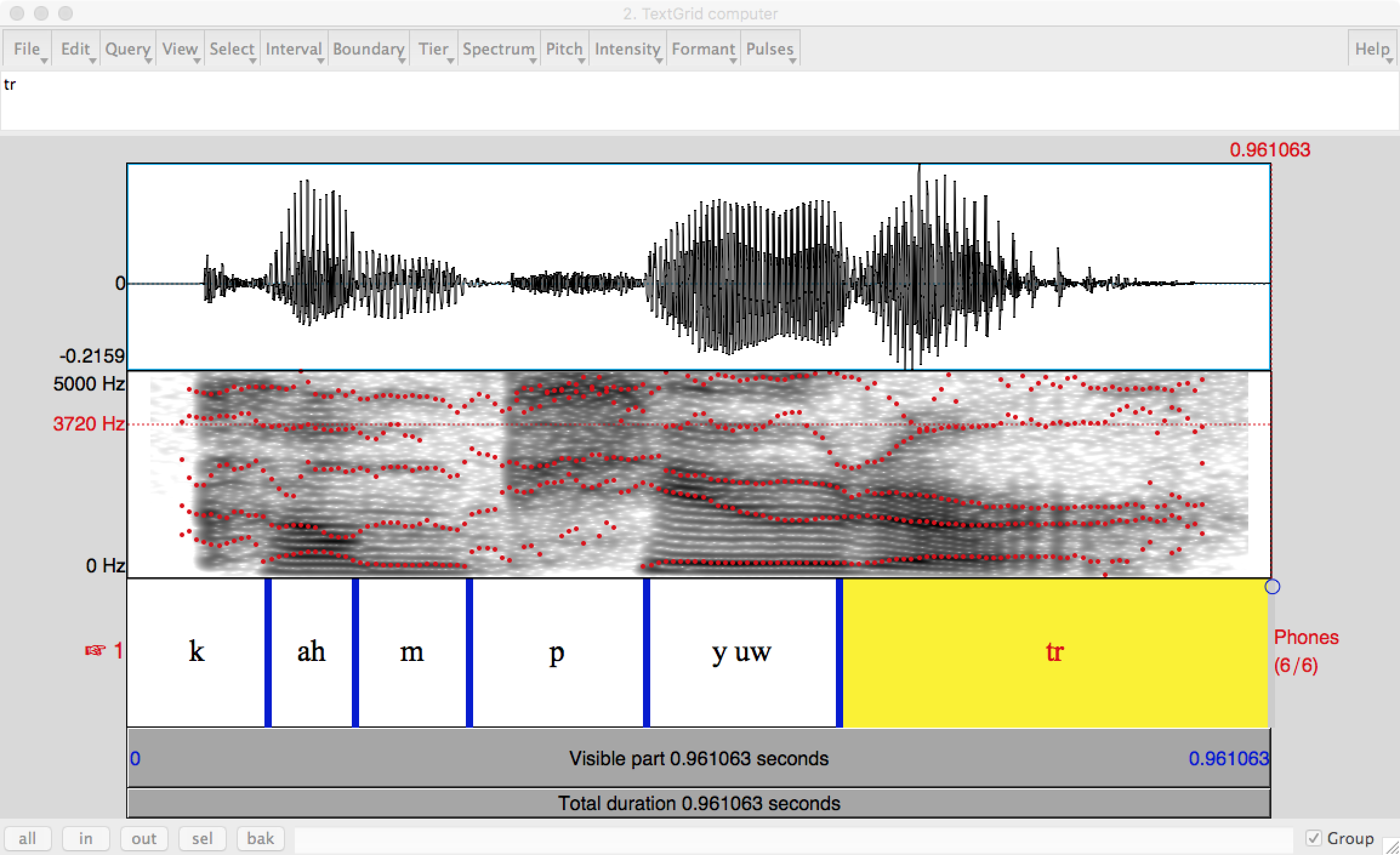
Models of human language understanding typically assume that a first stage that produces a reasonably accurate sequence of phones. The sequence of phones must then be segmented into a sequence of words by a "word segmentation" algorithm. The process might look like this, where # marks a literal pause in speech (e.g. the speaker taking a breath).
INPUT: ohlThikidsinner # ahrpiyp@lThA?HAvkids # ohrThADurHAviynqkids
OUTPUT: ohl Thi kids inner # ahr piyp@l ThA? HAv kids # ohr ThADur HAviynq kids
In standard written English, this would be "all the kids in there # are people that have kids # or that are having kids".
With current technology, the phone-level transcripts aren't accurate enough to do things this way. Instead, the final choice for each phone is determined by a combination of bottom-up signal processing and a statistical model of words and short word sequences. The methods are similar to the HMMs that we'll see soon for part of speech tagging.
If you have seen live transcripts of speeches (e.g. Obama's 2018 speech at UIUC) you'll know that there is still a significant error rate. This seems to be true whether they are produced by computers, humans, or (most likely) the two in collaboration. Highly-accurate systems (e.g. dictation) depend on knowing a lot about the speaker (how they normally pronounce words) and/or their acoustic environment (e.g. background noise) and/or what they will be talking about
A major challenge for speech recognition is that actual pronunciations of words frequently differ from their dictionary pronunciations. For example,
This kind of "phonological" change is part of the natural evolution of languages and dialects. Spelling conventions often reflect an older version of the language. Also, spelling systems often try to strike a middle ground among diverse dialects, so that written documents can be shared. The same is true, albeit to a lesser extent, of the pronunciations in dictionaries. These sound changes make it much harder to turn sequences of phones into words.
As we saw in the Naive Bayes lectures, different sorts of cleaning are required to make a clean stream of words from typical written text. We may also need to do similar post-processing to a speech recognizer's output. For example, the recognizer may be configured to transcribe into a sequence of short words (e.g. "base", "ball", "computer", "science") even when they form a tight meaning unit ("baseball" or "computer science"). Recognizers also faithfully reproduce disfluencies from the speaker (e.g. "um") and backchannels (e.g. "uh huh") from the listener. We may wish to remove these before later processing.
So, now, let's assume that we have a clean sequence of words. By "word," I mean a chunk of a size that's convenient for later algorithms (e.g. parsing, translation). This might be the output of a speech recognizer. Or, because many natural language systems don't start with speech, the stream of words might be (cleaned-up) written text.
These words then need to be divided into morphemes by a "morphology" algorithm. Words in some languages can get extremely long (e.g. Turkish), making it hard to do further processing unless they are (at least partly) subdivided into morphemes. For example:
unanswerable --> un-answer-able
preconditions --> pre-condition-s
Or, consider the following well-known Chinese word:
Zhōng + guó
In modern Chinese, this is one word ("China"). And our AI system would likely be able to accumulate enough information about China by treating it as one two-syllable item. But it is historically (and in the writing system) made from two morphemes ("middle" and "country"). It is what's called a "transparent compound," i.e. a speaker of the language would be aware of the separate pieces. This knowledge of the internal word structure would allow a human to guess that a less common word ending in "guo" might also be the name of a country.
Sometimes related words are formed by processes other than concatenation, e.g. the internal vowel change in English "foot" vs. "feet". When this is common in a language, we may wish to use a more abstract feature-based representation, e.g.
foot --> foot+SINGULAR
feet --> foot+PLURAL
Sometimes the appropriate division depends on the application. So the English possessive ending "'s" is traditionally written as part of the preceding word. However, it is often convenient to split it off as a separate word in later processing.
In order to group words into larger units (e.g. prepositional phrases), the first step is typically to assign a "part of speech" (POS) tag to each word. Here some sample text from the Brown corpus, which contains very clean written text.
Northern liberals are the chief supporters of civil rights and of integration. They have also led the nation in the direction of a welfare state.
Here's the tagged version. For example, "liberals" is an NNS which is a plural noun. "Northern" is an adjective (JJ). Tag sets need to distinguish major types of words (e.g. nouns vs. adjectives) and major variations e.g. singular vs plural nouns, present vs. past tense verbs. There are also some ad-hoc tags key function words, such as HV for "have," and punctuation (e.g. period).
Northern/jj liberals/nns are/ber the/at chief/jjs supporters/nns of/in civil/jj rights/nns and/cc of/in integration/nn ./. They/ppss have/hv also/rb led/vbn the/at nation/nn in/in the/at direction/nn of/in a/at welfare/nn state/nn ./.
Most words have only one common part of speech. So we can get up to about 91% accuracy using a simple "baseline" algorithm that always guesses the most common part of speech for each word. However, some words have more than one possible tag, e.g. "liberal" could be either a noun or an adjective. To get these right, we can use algorithms like hidden Markov models (next lecture). On clean text, a highly tuned POS tagger can get about 97% accuracy. In other words, POS taggers are quite reliable and mostly used as a stable starting place for further analysis.
Identifying a word's part of speech provides strong constraints on how later processing should treat the word. Or, viewed another way, the POS tags group together words that should be treated similarly in later processing. For example, in building parse trees, the POS tags povide direct information about the local syntactic structure, reducing the options that the parse must choose from.
Many early algorithms exploit POS tags directly (without building a parse tree) because the POS tag can help resolve ambiguities. For example, when translating, the noun "set" (i.e. collection) would be translated very differently from the verb "set" (i.e. put). The part of speech can distinguish words that are written the same but pronounced differently, such as:
Conversational spoken language also includes features not found in written language. In the example below (from the Switchboard corpus), you can see the filled pause "uh", also a broken off word "t-". Also, notice that the first sentence is broken up by a paranthetical comment ("you know") and the third sentence trails off at the end. Such features make spoken conversation harder to parse than written text.
I 'd be very very careful and , uh , you know , checking them out . Uh , our , had t- , place my mother in a nursing home . She had a rather massive stroke about , uh, about ---
I/PRP 'd/MD be/VB very/RB very/RB careful/JJ and/CC ,/, uh/UH ,/, you/PRP know/VBP ,/, checking/VBG them/PRP out/RP ./. Uh/UH ,/, our/PRP$ ,/, had/VBD t-/TO ,/, place/VB my/PRP$ mother/NN in/IN a/DT nursing/NN home/NN ./. She/PRP had/VBD a/DT rather/RB massive/JJ stroke/NN about/RB ,/, uh/UH ,/, about/RB --/:
Many useful systems can be built using only a simple local analysis of the word stream, e.g. words, word bigrams, morphemes, POS tags, perhaps a shallow parse (see below). These algorithms typically make a "Markov assumption," i.e. assume that only the last few items matter to the next decision. E.g.
Specific techniques include finite-state automata, hidden Markov models (HMMs), and recurrent neural nets (RNNs).
One we have POS tags for the words, we can assemble the words into a parse tree. There's many styles from building parse trees. Here are constituency trees showing two ways to group words in the phrase "green eggs and ham".
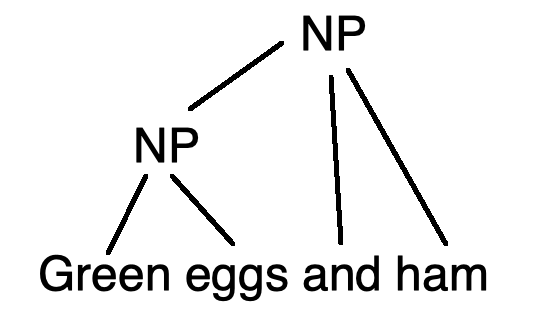
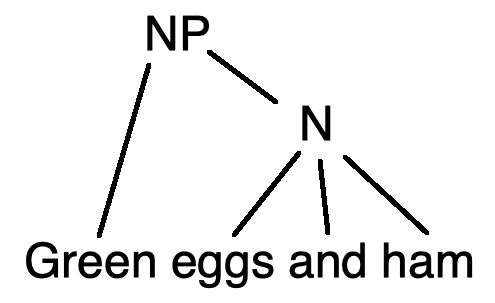
The lefthand grouping makes no claim about the color of the ham, whereas the righthand grouping claims it is green (like the eggs).
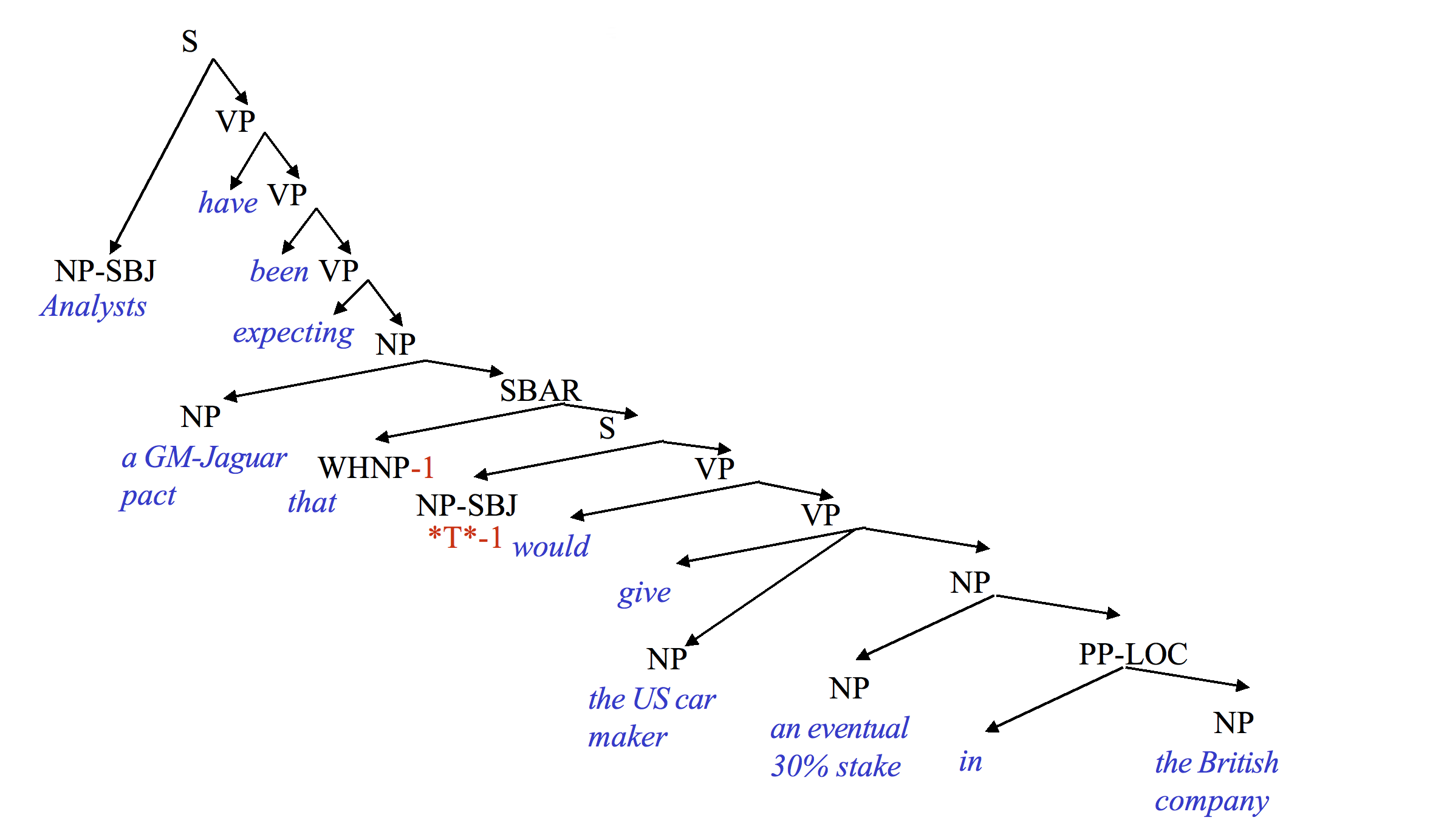
Here is a complex example from the Penn treebank (courtesy of Mitch Marcus).
An alternative is a dependency tree like the following ones below from Google labs.
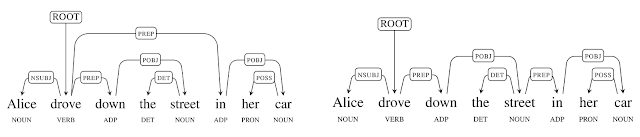
In this example, the lefthand tree shows the correct attachment for "in her car," i.e. modifying "drove." The righthand tree shows an interpretation in which the street is in the car.
Linguists (computational and otherwise) have extended fights about the best way to draw these trees. However, the information encoded is always fairly similar and primarily involves grouping together words that form coherent phrases e.g. "a welfare state." It's fairly similar to parsing computer programming languages, except that programming languages have been designed to make parsing easy.
A "shallow parser" builds only the lowest parts of such a tree. So it might group words into noun phrases, prepositional phrases, and complex verbs (e.g. "is walking"). Extracting these phrases is much easier than building the whole parse tree, and can be extremely useful for building shallow systems.
Like low-level algorithms, parsers often make their decisions using only a small amount of prior (and perhaps lookahead) context. However, "one item" of context might be a whole chunk of the parse tree. For example, "the talented young wizard" might be considered a single unit. Parsing algorithms must typically consider a wide space of options, e.g. many options for a partly-built tree. So they typically use beam search, i.e. keep only a fixed number of hypotheses with the best rating. Newer methods also try to share tree structure among competing alternatives (like dynamic programming) so they can store more hypotheses and avoid duplicative work.
 Boaty McBoatface (from the BBC)
Boaty McBoatface (from the BBC)
A fairly recent parser from Google was named "Parsey McParseface".
Parsers fall into three categories
The value of lexical information is illustrated by sentences like this, in which changing the noun phrase changes what the prepositional phrase modifies:
She was going down a street ..
in her truck. (modifies going)
in her new outfit. (modifies the subject)
in South Chicago. (modifies street)
The best parsers are lexicalized (accuracies up to 94% from Google's "Parsey McParseface" parser). But it's not clear how much information to include about the words and their meanings. For example, should "car" always behaves like "truck"? More detailed information helps make decisions (esp. attachment) but requires more training data.
Representation of meaning is less well understood. In modern systems, meaning of individual word stems (e.g. "cat" or "walk") is based on their observed context. We'll see details later in the term. But these meanings are not tied, or are only weakly tied, to the physical world. Methods for combining the meanings of individual words into a single meaning (e.g. "the red cat") are similarly fragile. Very few systems attempt to understand sophisticated constructions involving quantifiers ("How many arrows didn't hit the target?") or relative clauses. (An example of a relative clause is "that would give ..." in the Penn treebank parse example above.)
In classical AI systems, the high-level representation of meaning might look like mathematical logic. E.g.
in(Joe,kitchen) AND holding(Joe,cheese)
Or perhaps we have a set of objects and events, each containing values for a number of named slots:
event
name = "World War II"
type = war
years = (1939 1945)
participants = (Germany, France, ....)
This style of representation with slots and fillers is used to organize data like google's summaries of local restaurants (website, reviews, menu, opening hours, ...).
In modern systems based on neural nets, the high-level representation may look partly like a set of mysterious floating-point numbers. But these are intended to represent information at much the same level as the symbolic representations of meaning.
A specific issue for even simple applications is that negation is easy for humans but difficult for computers. For example, a google query for "Africa, not francophone" returns information on French-speaking parts of Africa. And this circular translation example shows Google making the following conversion which reverses the polarity of the advice. The critical mistake happens here:
Three types of shallow semantic analysis have proved useful and almost within current capabilities:
Semantic role labelling involves deciding how the main noun phrases in a clause relate to the verb. For example, in "John drove the car," "John" is the subject/agent and "the car" is the object being driven. Figuring out these relationships often involves syntax (sentence struture) as well as the meanings of the individual words. E.g. who is eating who in a "truck-eating bridge"?

a truck-eating bridge in Northampton MA
from Masslive.com
Right now, the most popular representation for word classes is a "word embedding." Word embeddings give each word a unique location in a high dimensional Euclidean space, set up so that similar words are close together. We'll see the details later. A popular algorithm is word2vec.
Running text contains a number of "named entities," i.e. nouns, pronouns, and noun phrases referring to people, organizations, and places. Co-reference resolution tries to identify which named entities refer to the same thing. For example, in this text from Wikipedia, we have identified three entities as referring to Michelle Obama, two as Barack Obama, and three as places that are neither of them. One source of difficulty is items such as the last "Obama," which looks superficially like it could be either of them.
[Michelle LaVaughn Robinson Obama] (born January 17, 1964) is an American lawyer, university administrator, and writer who served as the [First Lady of the United States] from 2009 to 2017. She is married to the [44th U.S. President], [Barack Obama], and was the first African-American First Lady. Raised on the South Side of [Chicago, Illinois], [Obama] is a graduate of [Princeton University] and [Harvard Law School].
Co-reference resolution is hard for computer algorithms, but centrally important for holding coherent conversations. When people are talking to one another, the first reference to an entity may be long and explicit, e.g. "Michelle Obama" or "the first white table in the front of the room." After that, the references are typically reduced to just enough information to allow the listener to identify the entity IN CONTEXT. Or sometimes not even that much.
People are sometimes confronted with the problem that references are ambiguous. For example, someone might be talking about two women and say something like "she told her to get a life". Which one is which? There are some useful rules for deciding, plus whatever context is available, but that's not always enough. People have (at least) three strategies for coping:
From a very young age, people have a strong ability to manage interactions over a long period of time. E.g. we can keep talking about a coherent theme (e.g. politics) for an entire evening. We can stay "on message," i.e. not switch our position on a topic. We can ask follow-on questions to build up a mental model in which all the pieces fit together. We expect all the pieces to fit together when reading a novel. Even the best modern AI systems cannot yet do this.
One specific task is "dialog coherency." For example, suppose you ask Google home a question like "How many calories in a banana?" It will give you a sensible answer (e.g. 105 calories). You might like to follow on with "How about an orange?" But most of these systems process each query separately, so they won't understand that your follow-up question is about calories. The exceptions can keep only a very short theory of context or (e.g. customer service systems) work in a very restricted domain. A more fun example of maintaining coherency in a restricted domain was the ILEX system for providing information about museum exhibits. ( original paper link)
The recent neural net system GPT-3 has a strong ability to maintain local coherency in its generated text and dialogs. However, this comes at a cost. Because it has no actual model of the world or its own beliefs, it can be led astray by leading questions.
A "shallow" system converts fairly directly between its input and output, e.g. a translation system that transforms phrases into new phrases without much understanding of what the input means.
One very old type of shallow system is spelling correction. Useful upgrades (which often work) include detection of grammar errors, adding vowels or diacritics in language (e.g. Arabic) where they are often omitted. Cutting-edge research problems involve automatic scoring of essay answers on standardized tests. Speech recognition has been used for evaluating English fluency and children learning to read (e.g. aloud). Success depends on very strong expectations about what the person will say.
Many of the useful current AI systems are shallow. That is, they process their input with little or no understanding of what it actually means. For example, suppose that you ask Google "How do I make zucchini kimchi?" or "Are tomatoes fruits?" Google doesn't actually answer the question but, instead, returns some paragraphs that seem likely to contain the answer. Shallow tools work well primarily because of the massive amount of data they have scraped off the web.
Similarly, summarization systems are typically shallow. These systems combine and select text from several stories, to produce a single short abstract. The user may read just the abstract, or decide to drill down and read some/all of the full stories. Google news is a good example of a robust summarization system. These systems make effective use of shallow methods, depending on the human to finish the job of understanding.
Text translations systems are often surprisingly shallow, with just enough depth of representation to handle changes in word order between languages. These systems depend on alignment algorithms which match two similar streams of text:
Alignment algorithms match two similar streams of text
Once we have alignnments, we can build algorithms to translate between the two representations. Translation is often done by shallow algorithms.
English: 18-year-olds can't buy alcohol.
French: Les 18 ans ne peuvent pas acheter d'alcool
| 18 | year | olds | can | 't | buy | alcohol | |||
| Les | 18 | ans | ne | peuvent | pas | acheter | d' | alcool |
Notice that some words don't have matches in the other language. For other pairs of languages, there could be radical changes in word order.
A corpus of matched sentence pairs can be used to build translation dictionaries (for phrases as well as words) and extract general knowledge about changes in word order.