Classifiers turn sets of input features into labels. At a very high level:
Classifiers can be used to classify static objects and to make decisions.
We've seen a naive Bayes classifier used to identify the type of text, e.g. label extracts such as the following as math text, news text, or historical document.
Let V be a particular set of vertices of cardinality n. How many different (simple, undirected) graphs are there with these n vertices? Here we will assume that we are naming the edges of the graph using a pair of vertices (so you cannot get new graphs by simply renaming edges). Briefly justify your answer. (from CS 173 study problems)
Senate Majority Leader Mitch McConnell did a round of interviews last week in which he said repealing Obamacare and making cuts to entitlement programs remain on his agenda. Democrats are already using his words against him. (from CNN, 21 October 2018)
Congress shall make no law respecting an establishment of religion, or prohibiting the free exercise thereof; or abridging the freedom of speech, or of the press; or the right of the people peaceably to assemble, and to petition the Government for a redress of grievances.
Classifiers can also be used label low-level input. For example, we can label what kind of object is in a picture. Or we can identify what phone has been said in each timeslice of a speech signal.
from Alex Krizhevsky's web page
"computer"
Classifiers can also be used to make decisions. For example, we might examine the state of a video game and decide whether to move left, move right, or jump. In the pictures below, we might want to decide if it's safe to move forwards along the path or predict what will happen to the piece of ginger.


Classifiers may also be used to make decisions internally to an AI system. Suppose that we have constructed the following parse tree and the next word we see is "Mary's".
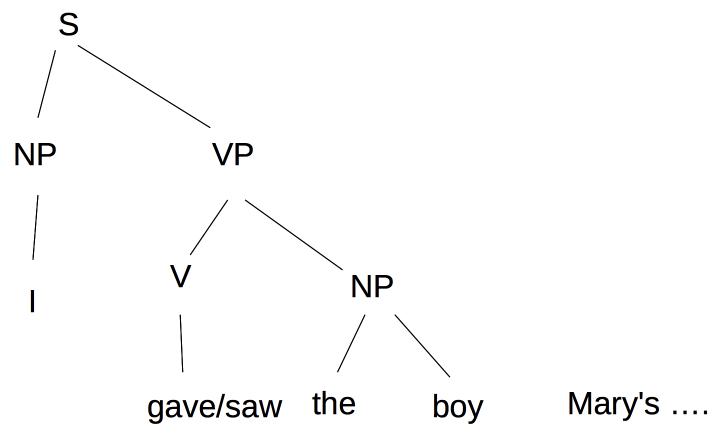
We have to decide how to attach "Mary's" into the parse tree. In "I gave the boy Mary's hat," "Mary's hat" will be attached to the VP as a direct object. In "I saw the boy Mary's going out with," the phrase "Mary's going out with" is a modifier on "boy." The right choice here depends on the verb (gave vs. saw) and lookahead at the words immediately following "Mary's".
Current algorithms require a clear (and fairly small) set of categories to classify into. That's largely what we'll assume in later lectures. But this assumption is problematic, and could create issues for deploying algorithms into the unconstrained real world.
For example, the four objects below are all quite similar, but nominally belong to three categories (peach, Asian pear, and two apples). How specific a label are we looking for, e.g. "fruit", "pear", or "Asian pear"? Should the two apples be given distinct labels, given that one is a Honeycrisp and one is a Granny Smith? Is the label "apple" correct for a plastic apple, or an apple core? Are some classification mistakes more/less acceptable than others? E.g. mislabelling the Asian pear as an apple seems better than calling it a banana, and a lot better than calling it a car.

What happens if we run into an unfamiliar type of object? Suppose, for example, that we have never seen an Asian pair. This problem comes up a lot, because people can be surprisingly dim about naming common objects, even in their first language. Do you know what a parsnip looks like? How about a plastron? Here is an amusing story about informant reliability from Robert M. Laughlin (1975, The Great Tzotzil Dictionary). In this situation, people often use the name of a familiar object, perhaps with a modifier, e.g. a parsnip might be "like a white carrot but it tastes different." Or they may identify the general type of object, e.g. "vegetable."

parsnips from Wikipedia
Some unfamiliar objects and activities can be described in terms of their components. E.g. the wind chime below has a big metal disk and some mysterious wood parts. The middle picture below is "a house with a shark sticking out of it." The bottom picture depicts ironing under water.



shark from
Wikipedia,
diver from
Sad and Useless
When labelling objects, people use context as well as intrinsic properties. This can be particularly important when naming a type of object whose appearance can vary substantially, e.g. the vases in the picture below.

A famous experiment by William Labov (1975, "The boundaries of words and their meanings") showed that the relative probabilities of two labels (e.g. cup vs. bowl) change gradually as properties (e.g. aspect ratio) are varied. For example, the tall container with no handle (left) is probably a vase. The round container on a stem (right) is probably a glass. But what are the two in the middle?

The very narrow container was sold as a vase. But filling it with liquid would encourage people to call it a glass (perhaps for a fancy liquor). Installing flowers in the narrow wine glass makes it seem more like a vase. And you probably didn't worry when I called it a "vase" above. The graph below (from the original paper) shows that imagining a food context makes the same picture more likely to be labelled as a bowl rather than a cup.

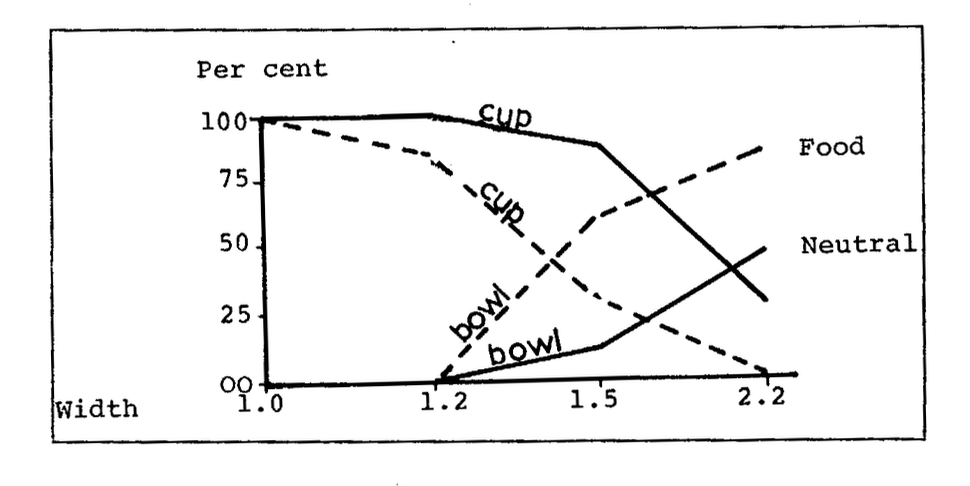
from William Labov (1975)
With complex scenes, it's not clear how many objects to explicitly call out. E.g. is the picture below showing a garden or a street? Are we supposed to be labelling each plant? Should we mark out the street lamp? The sidewalk?

When you're talking to another human, it's much more clear what aspects of the scene are important. First, there is usually some larger context that the conversation fits into (e.g. "gardening" or "traffic"). Second, people look at things they are interested in, e.g. compare the two pictures below. People have very strong ability to track another person's gaze as we watch what they are doing. Because of their close association with humans, the same applies to dogs. Using gaze to identify interest is believed to be an integral part of how children associate names with objects. Lack of appropriate eye contact is one reason that conversations feel glitchy on video conferencing systems.


It's tempting to see this problem as specific to computer vision. However, there are similar examples from other domains. E.g. in natural language processing, it's common to encounter new words. These can be unfamiliar proper nouns (e.g. "Gauteng", "covid"). Or they may be similar to familiar words, e.g. typos ("coputer") or new compounds ("astroboffin") or melds ("brexit", "splinch"). Phone recognition may involve more or less detail and mistakes may be minor (e.g. "t" vs. "d") or major (e.g. "t" vs. "a").
People use prosodic features (e.g. length, stress) to indicate which words are most important for the listener to pay attention to. And we use context to decide which meaning of a word is appropriate e.g. "banks" is interpreted very differently in "The pilot banks his airplane." vs. "Harvey banks at First Financial."
Classification begins with a choice of suitable features. For a picture, these might be the raw RGB intensity values, or they might be interesting points (e.g. corners, edges, eyes) picked out by an earlier level of processing. For text classification, they might be letters, words, parts of words, or groups of words. In some domains, the raw input signal is very large, e.g. we might want to describe the contents of a color image with 1000x1000 pixels, each containing three color values. Early processing often tries to reduce the dimensionality by picking out a smaller set of "most important" dimensions.
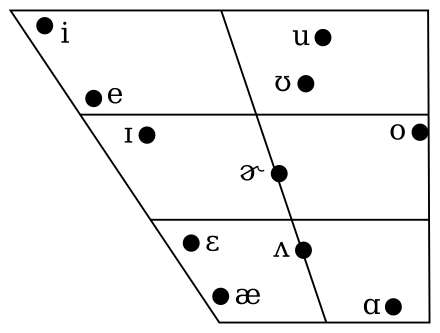
Vowels in speech can be classified based on two features: the frequencies of their first two formants (F1 and F2). (Recall: formants are bands of stronger energy in a frequency display of the speech waveform.) Here's an idealized picture of the English vowels for a California speaker, from Wikipedia.
From this, you might reasonable expect to experimental data to look like several tight clusters of points, well-separated. If that were true, then classification would be easy: model each cluster with a region of simple shape (e.g. ellipse), compare a new sample to these regions, and pick the one that contains the sample.
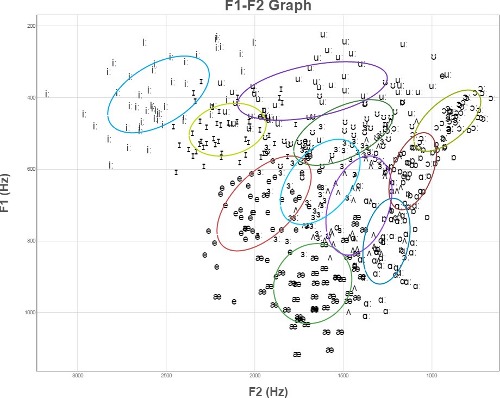
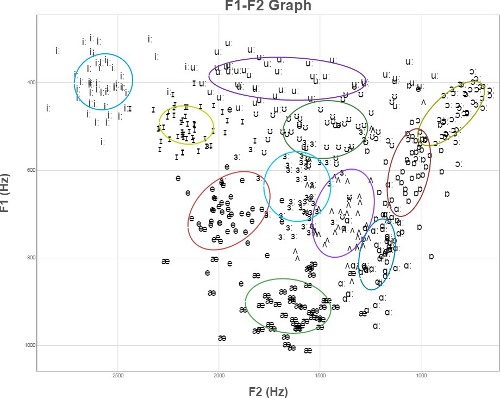
However, experimental datapoints for these vowels actually look more like the following picture. (This is from Experimental Phonetics course PALSG304 at UCL and shows vowels from 50 speakers of British English.)
When confronted with this type of messy data, our first job is to try to extract better features for our classifier. We could do this with a deterministic hand-coded process or with a second classifier layer. Both methods can be seen in current systems, e.g. for speech understanding.
Suppose that we take our raw F1 and F2 measurements for these British speakers and normalize them. Let's pick target values for the mean and standard deviation, and normalize the set of vowels for each speaker to have that mean and standard deviaion. This gives us better separation between the clusters for different English vowels.
Righthand picture is after normalization.
The data is still very messy. This is typical for input classification data. So we'll need to use classification methods that are robust to noise and variation. We also won't be able to expect perfect classification accuracy unless we can find other helpful features to use.
There are two basic approaches to each stage of processing:
Many real systems are a mix of the two. A likely architecture for a speech recognizer (e.g. the Kaldi system) would start by converting the raw signal to MFCC features, then use a neural net to identify phones, then use an HMM-type decoder to extract the most likely word sequence.
There are three basic types of classifiers with learned parameters. We've already seen the first type and we're about to move onto the other three
Classifiers typically have a number of overt variables that can be manipulated to produce the best outputs. These fall into two types:
Researchers also tune the structure of the model.
It is now common to use automated scripts to tune hyperparameters and some aspects of the model structure. Tuning these additional values is a big reason why state-of-the-art neural nets are so expensive to tune. All of these tunable values should be considered when assessing whether the model could potentially be over-fit to the training/development data, and therefore might not generalize well to slightly different test data.
Training and testing can be interleaved to varying extents:
Incremental training is typically used by algorithms that must interact with the world before they have finished learning. E.g. children need to interact with their parents from birth, long before their language skills are fully mature. Sometimes interaction is to get their training data. E.g. a video game player may need to play experimental games. Incremental training algorithms are typically evaluated based on their performance towards the end of training.
When training a classifier, we can have it adjust its parameters each time it sees a piece of training data. Alternatively, we can process a whole "batch" or "mini-batch" of training data and adjust the model parameters only after we've seen the results for all of them. The second method is frequently more efficient. Notice that this use of "batch" is different from the one we just saw. (sigh)
Traditionally, most classifiers used "supervised" training. That is, someone gives the learning algorithm a set of training examples, together with correct ("gold") output for each one. This is very convenient, and it is the setting in which we'll learn classifier techniques. But this only works when you have enough labelled training data. Usually the amount of training data is inadequate, because manual annotations are slow and expensive to produce.
Moreover, labelled data is always noisy. Algorithms must be robust to annotation mistakes. It may be impossible to reach 100% accuracy because the gold standard answers aren't entirely correct.
Finally, large quantities of correct answers may be available only for the system as a whole, not for individual layers. Marking up correct answers for intermediate layers frequently requires expert knowledge, so cannot easily be farmed out to students or internet workers.
Researchers have a used a number of methods to work around lack of explicit labelled training data. For example, current neural net software lets us train the entire multi-layer as a unit. Then we need correct outputs only for the final layer. This type of training optimizes the early layers only for this specific task. However, it may be possible to quickly adapt this "pre-trained" layer for use in another task, using only a modest amount of new training data for the new task.
For example, the image colorization algorithm shown below learns how to add color to black and white images. The features it exploits in the monochrome images can also (as it turns out) be used for object tracking.


from Zhang, Isola, Efros
Colorful Image Colorization
For this colorization task, the training pairs were produced by removing color from
color pictures. That is, we subtracted information and learned to restore it.
This trick for producing training pairs has been used elsewhere. For example, the
BERT system trains natural language models by masking off words in training sentences,
and learning to predict what they were. Similarly, the pictures below illustrate
that we can learn to fill in missing image content, by creating training images with
part of the content masked off.

from Pathak et al. "Context Encoders: Feature Learning by
Inpainting"
Another approach is self-supervision, in which the learner experiments with the world to find out new information. Examples of self-supervision include
The main challenge for self-supervised methods is designing ways for a robot to interact with a real, or at least realistic, world without making it too easy for the robot to break things, injury itself, or hurt people.
"Semi-supervised" algorithms extract patterns from unannotated data, combining this with limited amounts of annotated data. For example, a translation algorithm needs some parallel data from the two languages to create rough translations. The output can be made more fluent by using unannotated data to learn more about what word patterns are/aren't appropriate for the output language. Similarly, we can take observed pauses in speech and extrapolate the full set of locations where it is appropriate to pause (i.e. word boundaries).
"Unsupervised" algorithms extract patterns entirely from unannotated data. These are much less common than semi-supervised methods. Sometimes so-called unsupervised methos actually have some implicit supervision (e.g. sentence boundaries for a parsing algorithm). Sometimes they are based on very strong theoretical assumptions about how the input must be structured.