Computer vision algorithms relate image data to high-level descriptions. Although the techniques are generally similar to those in natural language, the objects being manipulated are in 2D or 3D.
Cameras and human eyes map part of the 3D world onto a 2D picture. The picture below shows the basic process for a pinhole camera. Light rays pass through the pinhole (P) and form an image on the camera's sensor array. When we're discussing geometry rather than camera hardware, it's often convenient to think of a mathematical image that lives in front of the pinhole. The two images are similar, except that the one behind the pinhole is upside down.
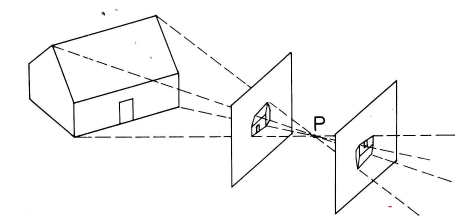 from Rudolf Kingslake, Optics in Photography
from Rudolf Kingslake, Optics in Photography
Pinhole cameras are mathematically simple but don't allow much light through. So cameras use a lens to focus light coming in from a wider aperture. Typical camera lenses are built up out of multiple simple lenses. In the wide-angle lens shown below, a bundle of light rays coming from the original 3D location enters the front element at the left and is gradually focused into a single point on the image at the right.
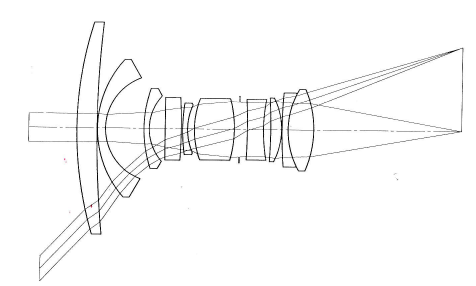 from Rudolf Kingslake, Optics in Photography
from Rudolf Kingslake, Optics in Photography
The human eye has a simpler lens, but also an easier task. At any given moment, only a tiny area in the center of your field of view is in sharp focus and, even within that area, objects are only in focus if they are at the depth you're paying attention to. The illusion of a wide field of view in sharp focus is created by the fact that your eyes constantly change their direction and focal depth, as your interest moves around the scene.
 from Wikipedia
from Wikipedia
The lens produces a continuous image on the camera. Digital cameras sample this to produce a 2D array of intensity values. A filter array sends red, green, or blue light preferentially to each (x,y) location in the sensor array, in an alternating pattern. This information is reformatted into an output in which each (x,y) position contains a "pixel" with three color values (red, green, and blue). Modern cameras produce images that are several thousand pixels wide and high, i.e. much more resolution than AI algorithms can actually handle.
The human retina uses variable-resolution sampling. The central region (fovea) is used for seeing fine details of the object that you're paying attention to. The periphery provides only a coarse resolution picture and is used primarily for navigational tasks such as not running into tables and staying 6' away from other people.
The lefthand photomicrograph below shows the pattern of cone cells in the fovea. The righthand picture shows the cones (large cells) in the periphery, interspersed with rods (small cells). Notice that the pattern is slightly irregular, which prevents aliasing artifacts. "Aliasing" is the creation of spurious low-frequency patterns from high-frequency patterns that have been sampled at too low a frequency.
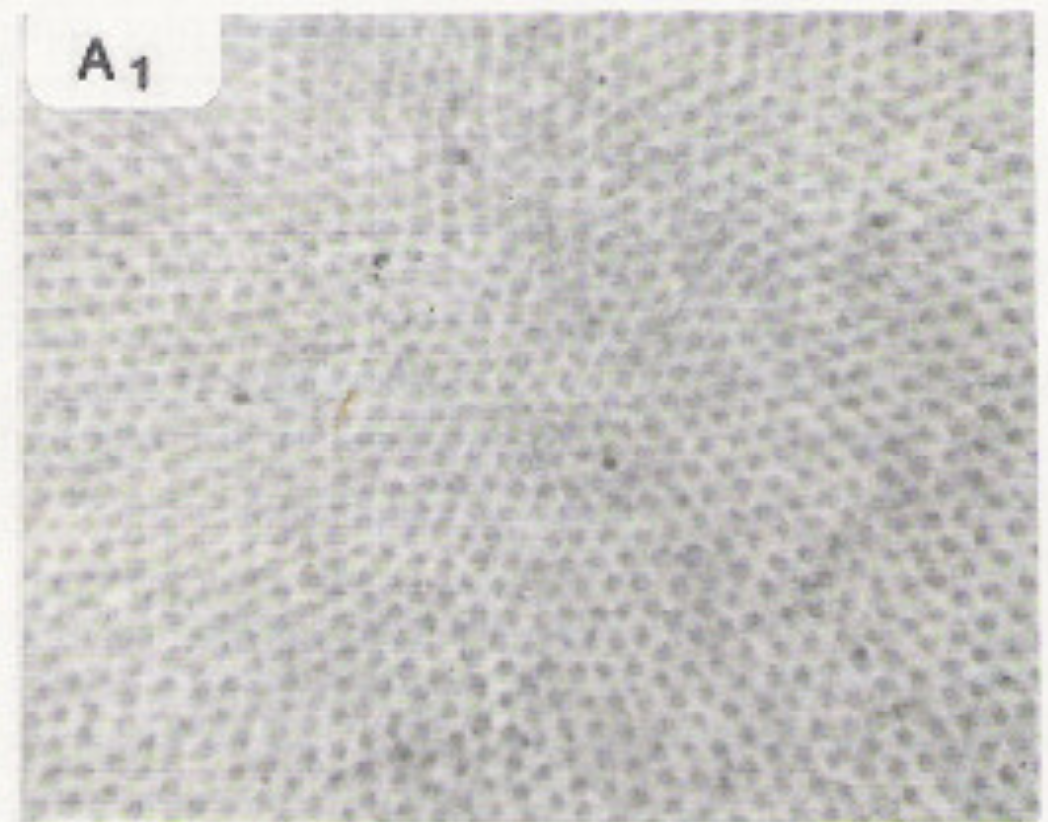
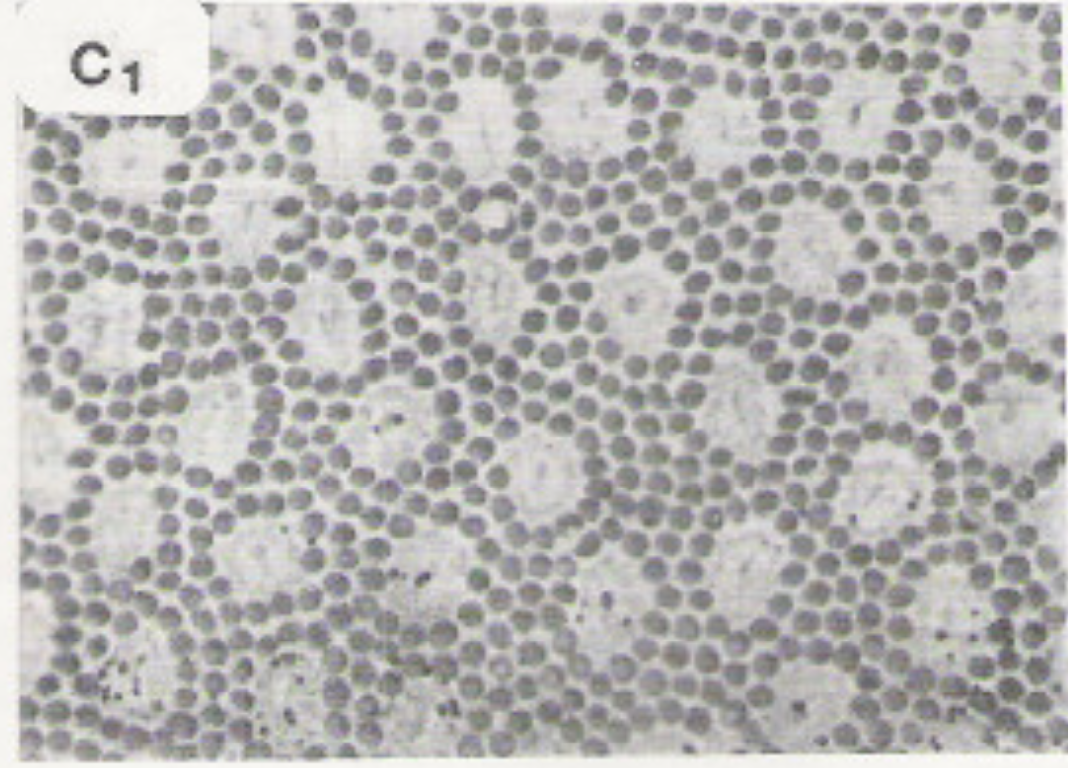
Photomicrographs
from John Yellott, "Spectral Consequences of Photoreceptor Sampling in the
Rhesus Retina"
Each type of receptor responds preferentially to one range of light colors, as shown below. The red, green, and blue cones produce outputs similar to the ones from a digital camera, except that blue cones are much less common than blue and green ones. The rods (only one color type) are used for seeing in low-light conditions.
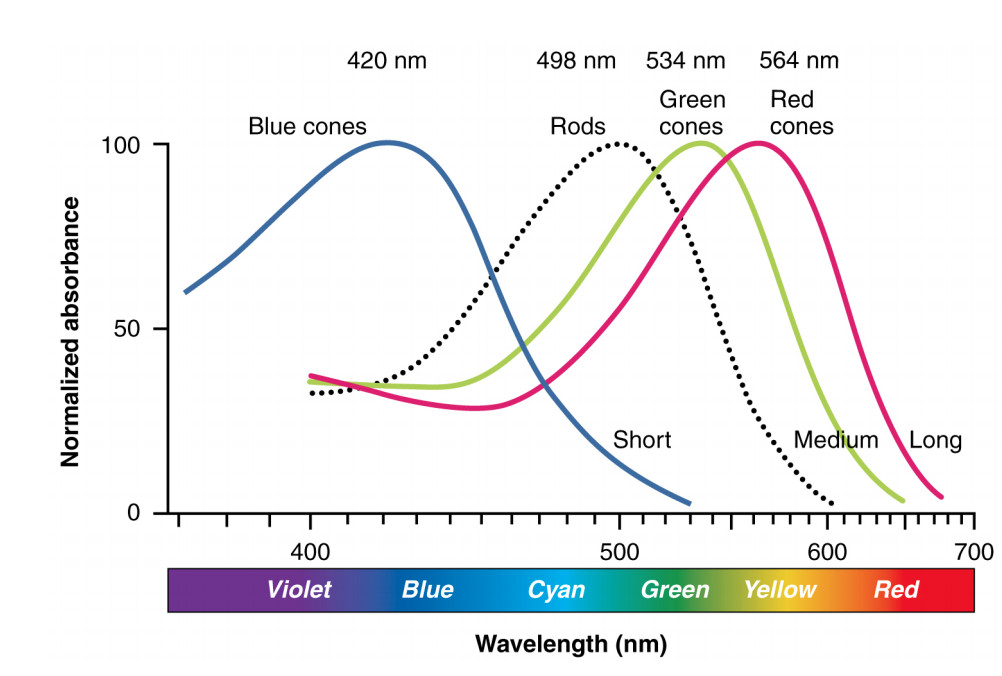
Illustration from Anatomy & Physiology, Connexions Web site. http://cnx.org/content/col11496/1.6/, Jun 19, 2013.
Recognizing objects from pictures is difficult because "the same" object never actually has the same pattern of pixel values. Most obviously, we could rotate or translate the position of the object in the picture.


But, in addition, we might be seeing the object from two different viewpoints. This is what happens if I simply translate my camera toward a coffee mug. The closeup view in the second picture makes the top of the cup seem much wider than the bottom. This sort of distortion is why selfies look strange. Professional portraits are typically taken from further away. Depending on specifics of the camera lens, simply moving the object from the middle to the edge of the view can also cause its shape to be distorted.


Compare the two views of the lemon tree (in the planter) and the fig tree behind it. Pictures of complex objects can look very different from different viewpoints.

|

|

|
| lemon (front) fig (back) | closeup of lemon | closeup of fig |
Parts of objects can be "occluded," i.e. disappear behind other objects

Moving the joints of an objects changes it shape. A flexible object can be bent into different shapes



Differences in lighting can change the apparent color of an object, as well as the positions of highlights and shadows. The two pictures below are the same apple, photographed in different rooms. The apple looks like it's a different colors when the lighting changes. Also, the lefthand picture has a dark shadow above the apple, whereas the righthand picture (taken in more diffuse lighting) has a light shadow below the apple.


When the eye or camera brings one part of a scene into focus, other parts may be thrown out of focus. This "accommodation" by the eye or camera is another reason why the same object can look different in two pictures.


Finally, natural objects are rarely identical, even when they are nominally of the same type, e.g. the two honeycrisp apples below.

Computer vision can used for four basic types of tasks:
Some predictions require sophisticated understanding of the scene. But, interestingly, others do not. Here's a picture of a tree branch that I'm about to run into.

If an object is moving directly towards you, it expands in your field of view without moving sideways. Moreover, the time to collision is its size in the image times the derivative of the size. Humans and many other animals use this trick to quickly detect potential collisions. Collision avoidance is one of the main roles of the low-resolution peripheral vision in humans.
In its most basic form, classification involves coming up with a single label to describe the contents of an image. For example, the lefthand picture below shows an apple; the righthand picture shows a mug.

Using deep neural networks, top-5 error rates for classification on Imagenet (one standard benchmark set of labelled images) have gone from 27% in 2010 to <5% in 2015. Unfortunately, we have a rather poor model of why these networks work well, and how to construct good ones. As we will see later on, neural nets also have a tendency to fail unexpectedly.
Recently, classifiers have been extended to work on more complex scenes. This involves two tasks which could theoretically be done as one step but frequently are not. First, we detect objects along with their approximate location in the image, producing a labelled image like the one below. This uses a lot of classifiers and works only on smallish sets of object types (e.g. tens, hundreds).

from Lana Lazebnik
When an object is mentioned in an image caption, similar methods can be used to locate the object in the image. After an object has been detected and approximately located, we can "register" it. That is, we can produce its exact position, pose, orientation.
There has also been some success at labelling "semantic" roles in images, e.g. who is the actor? what are they acting on? what tool are they using? In the examples below, you can see that many roles are successfully recovered (green) but some are not (red). This kind of scene analysis can be used to generate captions for images and answer questions about what's in a picture.

from Yatskar, Zettlemoyer, Farhadi, "Situation Recognition" (2016)
We can also reconstruct aspects of the 3D scene, without necessarily doing a deeper analysis or associating any natural language labels. Suppose, for example, that we have two pictures of a scene, either from a stereo pair of cameras or a moving camera. Notice that distant objects stay in approximately the same image position but closer objects move significantly.


It's fairly common that we know the relative positions of the two cameras. For example, they may both be mounted on the same robot platform. Human eyes are another example. In this situation, it's easy to turn a pair of matching features into a depth estimate. (See diagram below.) These depth estimates are highly accurate for objects near the observer, which conveniently matches what we need for manipulating objects that are within grabbing distance. People who lack stereo vision can get similar information by moving their heads.
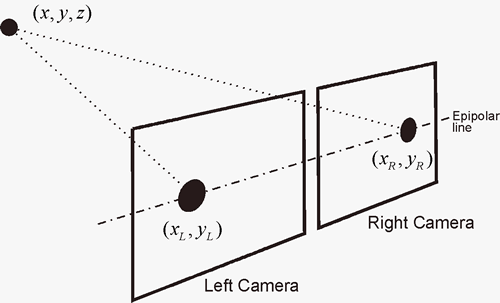
from Derek Hoiem
More interestingly, we can reconstruct the camera motion if we have enough matched features. For example, we can extract local features from a pair of images and use these as guidepoints to merge the two images into one. We can reconstruct a 3D scene down to very fine details if we have enough pictures. So we can send a drone into a space that is hazardous or inconvenient for humans to visit, and then direct a human inspector to problematic features (e.g. evidence of cracking in bridge supports).


from Derek Hoiem

from Derek Hoiem
When you have enough training examples, or enough prior knowledge, it's possible to reconstruct 3D information from a single image. For example, a mobile robot might extract the sides of this path, use their vanishing point to guess the tilt, and figure out that the blue object is something that might block its route. In this case, it's a jacket, so some robots might be able to drive over it. But it could have been a large rock.

More interestingly, we can extract a 3D model for indoor scenes using our knowledge of typical room geometry, likely objects, etc. In the picture below, a program has outlined the edges delimiting the floor, ceiling, and walls.

from Derek Hoiem
Relatively recent neural net algorithms can create random images similar to a set of training images. This can be done for fun (e.g. the faces below). A serious application is creating medical images that can be for teaching/research, without giving away private medical data. Can work very well: doctors find it very hard to tell real xray images from fake ones.

from StyleGAN by Karras, Laine, Aila (NVIDIA) 2019
More interestingly, suppose that we have a 3D model for the scene. We now have enough information to add objects to the scene and make the result look right. (See picture below.) The 3D model is required to make objects sit correctly on surfaces (rather than hovering somewhere near them), give the object appropriate shading, and make light from (or bouncing off of) the object affect the shading on nearby objects. We can also remove objects, by making assumptions about what surface(s) probably continue behind them. And we can move objects from one picture into another.

Karsh, Hedau, Forsyth, Hoiem "Rendering Synthetic Objects into
Legacy Photographs" (2011)
Here is a cool video showing details of how this algorithm works (from Kevin Karsh).
A much harder, but potentially more useful, task would be to predict the future from our current observations. For example, what's about to happen to the piece of ginger in the picture below?

What's going to happen here?