Computer vision algorithms relate image data to high-level descriptions. Although the techniques are generally similar to those in natural language, the objects being manipulated are in 2D or 3D.
Cameras and human eyes map part of the 3D world onto a 2D picture. The picture below shows the basic process for a pinhole camera. Light rays pass through the pinhole (P) and form an image on the camera's sensor array. When we're discussing geometry rather than camera hardware, it's often convenient to think of a mathematical image that lives in front of the pinhole. The two images are similar, except that the one behind the pinhole is upside down.
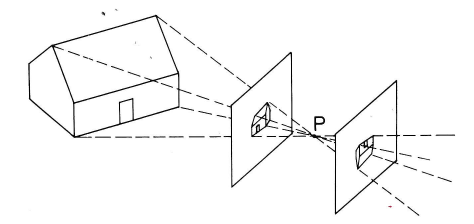 from Kingslake, Optics in Photography
from Kingslake, Optics in Photography
Pinhole cameras are mathematically simple but don't allow much light through. So cameras use a lens to focus light coming in from a wider aperture. Typical camera lenses are built up out of multiple simple lenses. In the wide-angle lens shown below, a bundle of light rays coming from the original 3D location enters the front element at the left and is gradually focused into a single point on the image at the right.
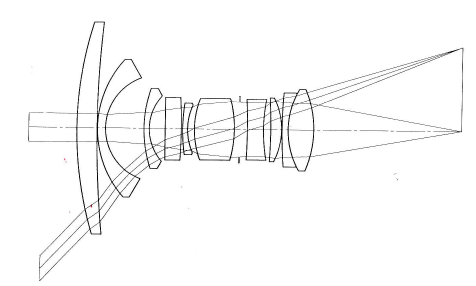 from Kingslake, Optics in Photography
from Kingslake, Optics in Photography
The human eye has a simpler lens, but also an easier task. At any given moment, only a tiny area in the center of your field of view is in sharp focus and, even within that area, objects are only in focus if they are at the depth you're paying attention to. The illusion of a wide field of view in sharp focus is created by the fact that your eyes constantly change their direction and focal depth, as your interest moves around the scene.
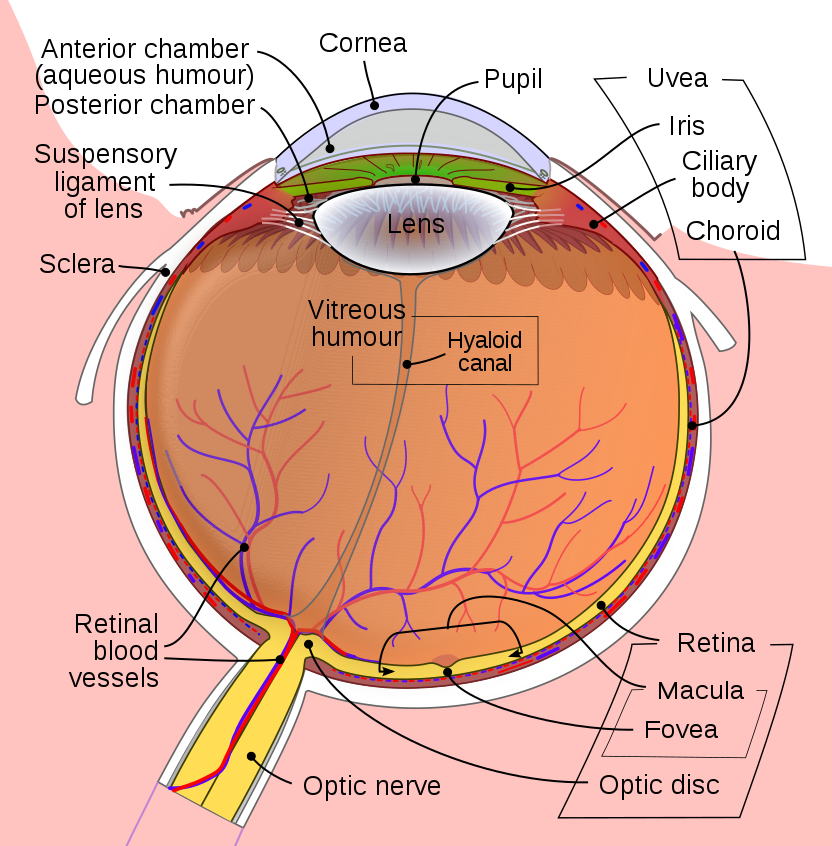 from Wikipedia
from Wikipedia
The lens produces a continuous image on the camera. Digital cameras sample this to produce a 2D array of intensity values. A filter array sends red, green, or blue light preferentially to each (x,y) location in the sensor array, in an alternating pattern. This information is reformatted into an output in which each (x,y) position contains a "pixel" with three color values (red, green, and blue). Modern cameras produce images that are several thousand pixels wide and high, i.e. much more resolution than AI algorithms can actually handle.
The human retina uses variable-resolution sampling. The central region (fovea) is used for seeing fine details of the object that you're paying attention to. The periphery provides only a coarse resolution picture and is used primarily for navigational tasks such as not running into tables and staying 6' away from other people.
The lefthand photomicrograph below shows the pattern of cone cells in the fovea. The righthand picture shows the cones (large cells) in the periphery, interspersed with rods (small cells). Notice that the pattern is slightly irregular, which prevents aliasing artifacts. "Aliasing" is the creation of spurious low-frequency patterns from high-frequency patterns that have been sampled at too low a frequency.
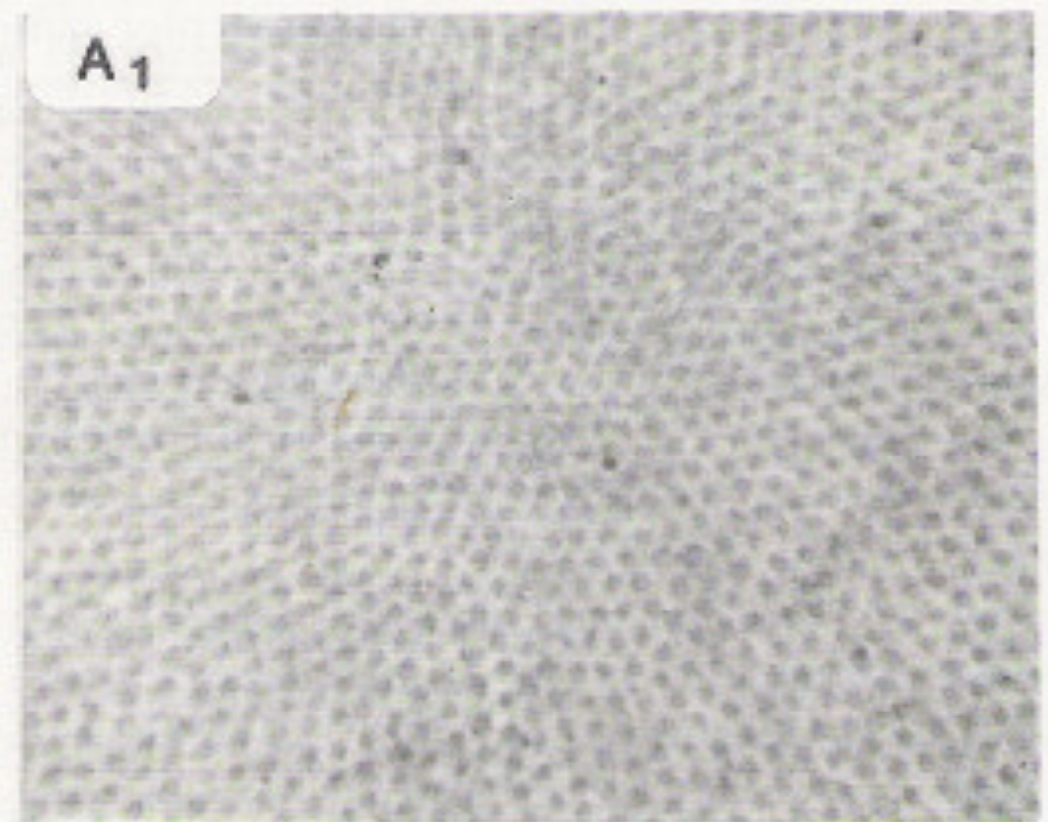
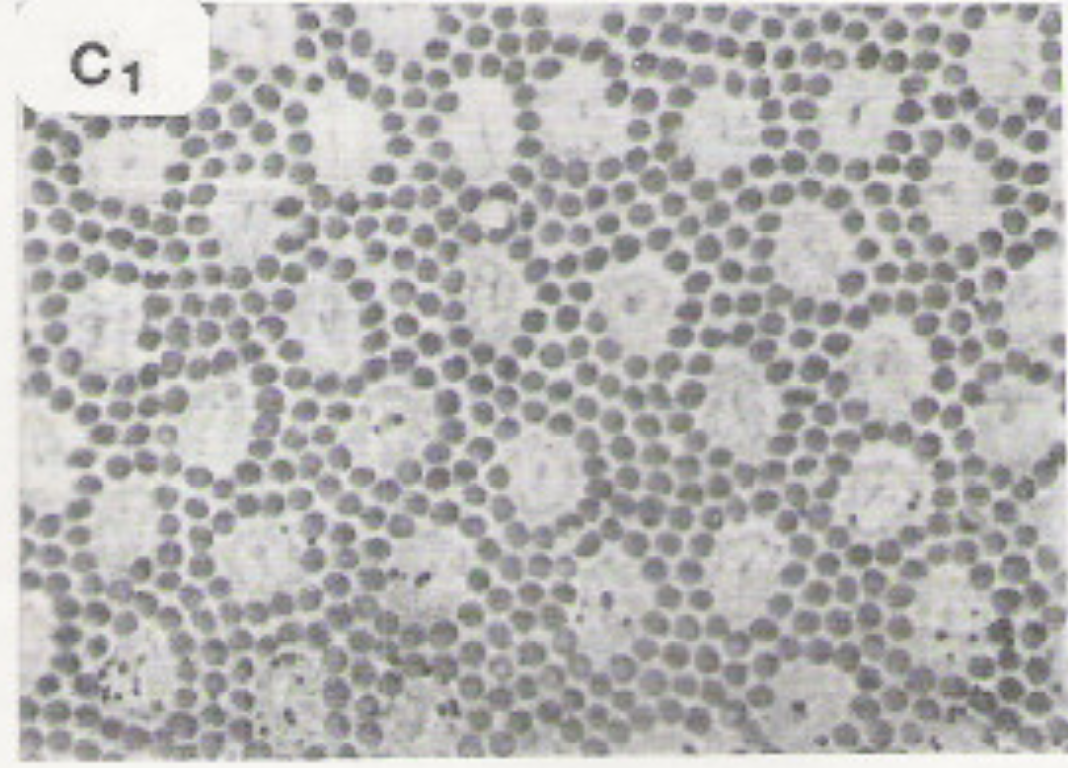
Photomicrographs
from John Yellott, "Spectral Consequences of Photoreceptor Sampling in the
Rhesus Retina"
Each type of receptor responds preferentially to one range of light colors, as shown below. The red, green, and blue cones produce outputs similar to the ones from a digital camera, except that blue cones are much less common than blue and green ones. The rods (only one color type) are used for seeing in low-light conditions.
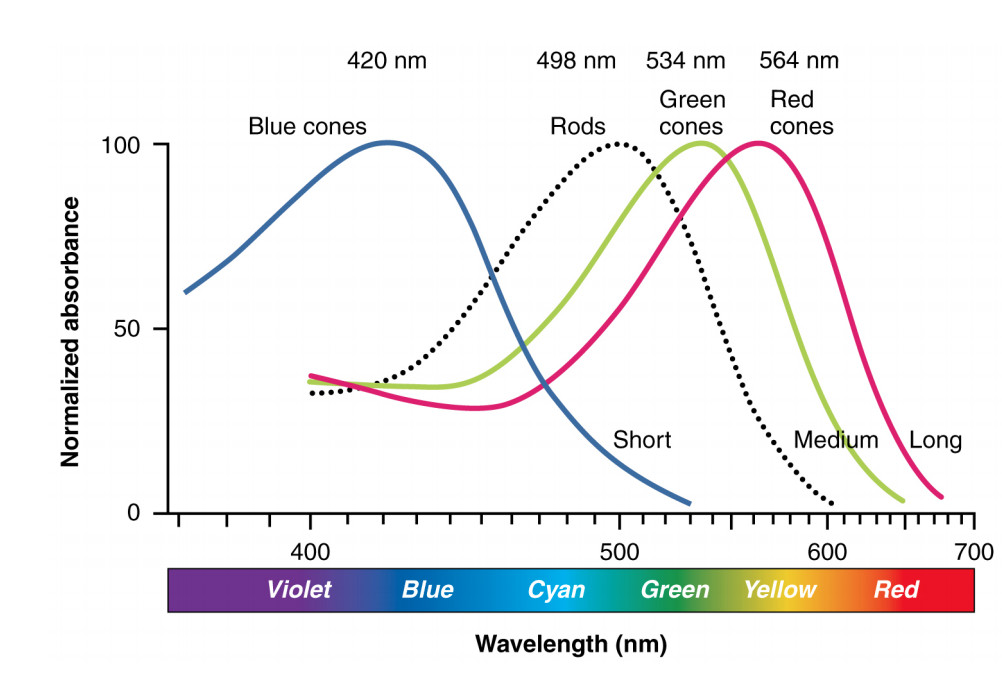
Illustration from Anatomy & Physiology, Connexions Web site. http://cnx.org/content/col11496/1.6/, Jun 19, 2013.
Recognizing objects from pictures is difficult because "the same" object never actually has the same pattern of pixel values. Most obviously, we could rotate or translate the position of the object in the picture. But, in addition, we might be seeing the object from two different viewpoints. E.g. compare the two views of the lemon tree (in the planter) and the fig tree (left plant in the righthand picture). Depending on specifics of the camera lens, simply moving the object from the middle to the edge of the view can also cause its shape to be distorted. The shape of an object looks different when it's seen from very close, e.g. a selfie vs. a professional photograph.



Parts of objects can be "occluded," i.e. disappear behind other objects (apple in the lefthand picture). A flexible object can be bent into different shapes (right below).


Differences in lighting can change the apparent color of an object, as well as the positions of highlights and shadows. The two pictures below are the same apple, photographed in different rooms. The apparent colors are different. Also, the lefthand picture has a dark shadow above the apple, whereas the righthand picture (taken in more diffuse lighting) has a light shadow below the apple.


Finally, natural objects are rarely identical, even when they are nominally of the same type, e.g. the two honeycrisp apples below.
