We can now set up the full "temporal difference" algorithm for choosing actions while learning the Q values.
The obvious choice for an action to command in step 1 is
\( \pi(s) = \text{argmax}_{a} Q(s,a) \)
But recall from a previous lecture that the agent also needs to explore. So a better method is
The best balance between these two possibilities depends on the state and action. We should do more random exploration in states that haven't been sufficiently explored, with a bias towards choosing actions that haven't been sufficiently explored.
Adding exploration creates an inconsistency in our TD algorithm.
So the update in step 3 is based on a different action from the one actually chosen by the agent. In particular, our construction of the update method assumes that we always followed our currently best policy pi, but our action selection method also includes exploration. So occasionally the agent does random things that don't follow policy.
The SARSA ("State-Action-Reward-State-Action") algorithm adjusts the TD algorithm to align the update with the actual choice of action. The algorithm looks like this, where (s,a) is our current state and action and (s',a') is the following state and action.
So we're unrolling a bit more of the state-action sequence before doing the update. Our update uses the actions that the agent chose rather than maximizing over all possible actions that the agent might choose.
Here's an example from Travis DeWolf that nicely illustrates the difference between SARSA and TD update. The agent is prone to occasional random motions, because it likes to explore rather than just following its optimal policy. The TD algorithm assumes it will do a better job of following policy, so it sends the agent along the edge of the hazard and it regularly falls in. The SARSA agent (correctly) doesn't trust that it will stick to its own policy. So it stays further from the hazard, so that the occasional random motion isn't likely to be damaging.
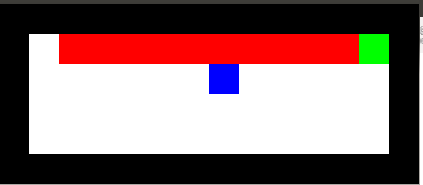
Mouse (blue) tries to get cheese (green) without falling in the pit of fire (red).
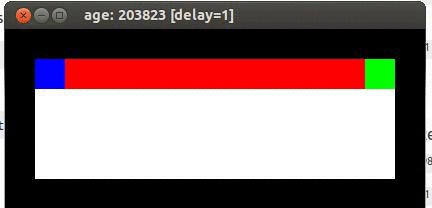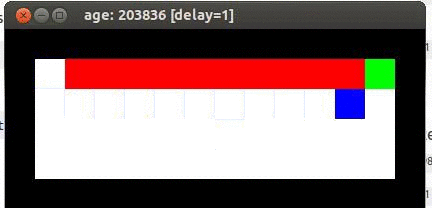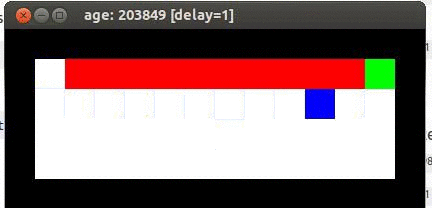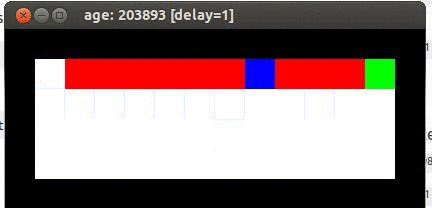
Trained using TD update
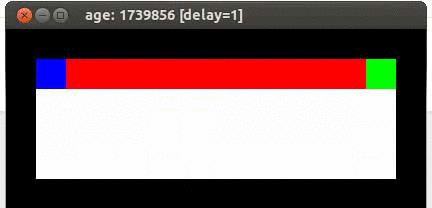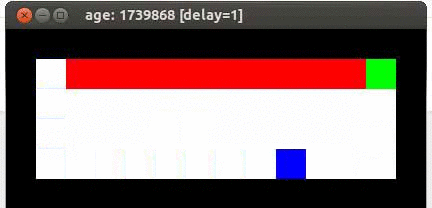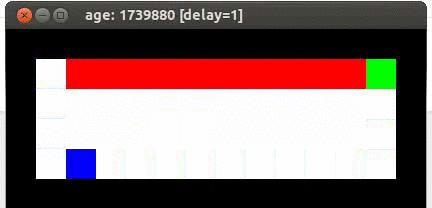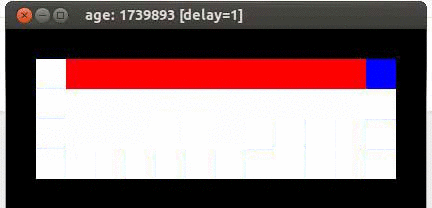
Trained using SARSA
There are many variations on reinforcement learning. Especially interesting ones include
Spider robot from Yamabuchi et al 2013
playing Atari games (V. Mnih et al, Nature, February 2015)