The NLP processing pipeline looks roughly like this:
Text-only processing omits the speech step. Shallow systems operate directly on the low-level or mid-level representations, omitting semantics.
Some useful definitions
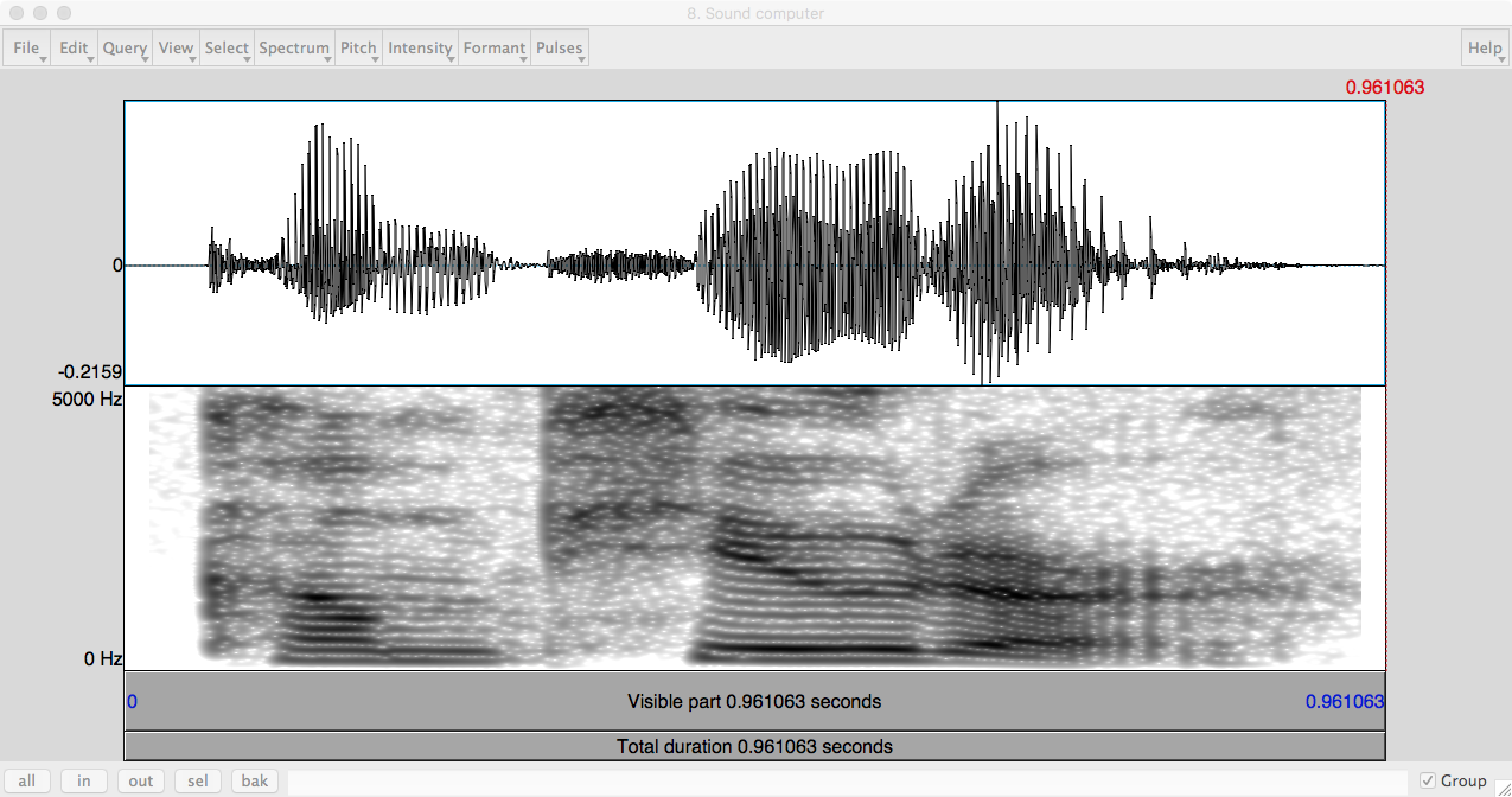
The first "speech recognition" layer of processing turns speech (e.g. the waveform at the top of this page) into a sequence of phones (basic units of sound). We first process the waveform to bring out features important for recognition. The spectogram (bottom part of the figure) shows the energy at each frequency as a function of time, creating a human-friendly picture of the signal. Computer programs use something similar, but further processed into a small set of numerical features.
Each phone shows up in characteristic ways in the spectrogram. Stop consonants (t, p, ...) create a brief silence. Fricatives (e.g. s) have high-frequency random noise. Vowels and semi-vowels (e.g. n, r) have strong bands ("formants") at a small set of frequencies. The location of these bands and their changes over time tell you which vowel or semi-vowel it is.
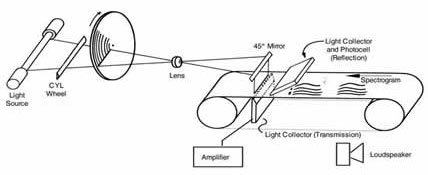
Recognition is harder than generation. However, generation is not as easy as you might think. Very early speech synthesis (1940's, Haskins Lab) was done by painting pictures of formants onto a sheet of plastic and using a physical transducer called the Pattern Playback to convert them into sounds.
Synthesis moved to computers once these became usable. One technique (formant synthesis) reconstructs sounds from formats and/or a model of the vocal tract. Another technique (concatenative synthesis) splices together short samples of actual speech, to form extended utterances.
The voice of Hal singing "Bicycle built for two" in the movie "2001" (1968) was actually a fake, rather than real synthesizer output from the time.
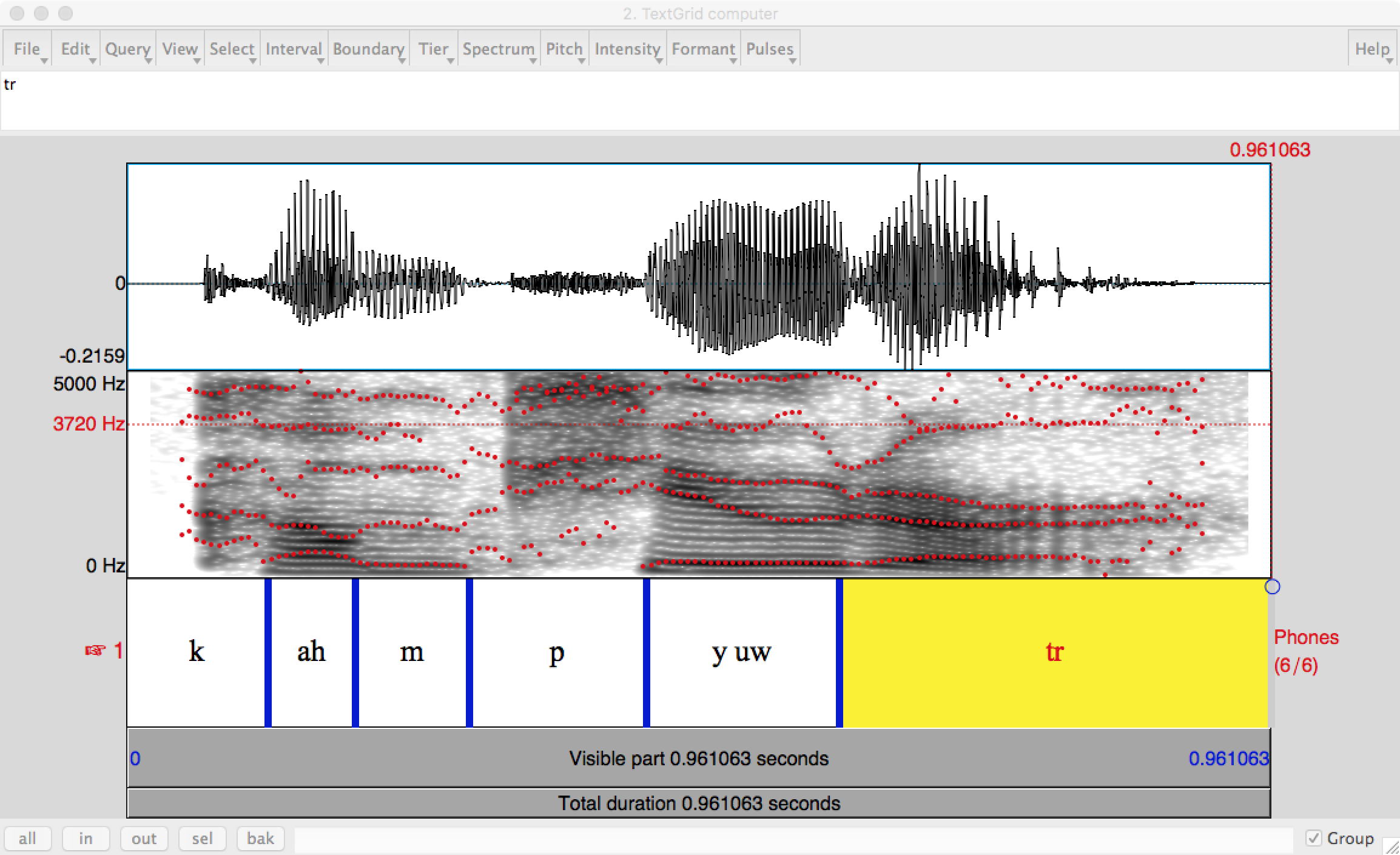
Models of human language understanding typically assume that a first stage that produces a reasonably accurate sequence of phones. The sequence of phones must then be segmented into a sequence of words by a "word segmentation" algorithm. The process might look like this, where # marks a literal pause in speech (e.g. the speaker taking a breath).
INPUT: ohlThikidsinner # ahrpiyp@lThA?HAvkids # ohrThADurHAviynqkids
OUTPUT: ohl Thi kids inner # ahr piyp@l ThA? HAv kids # ohr ThADur HAviynq kids
In standard written English, this would be "all the kids in there # are people that have kids # or that are having kids".
With current technology, the phone-level transcripts aren't accurate enough to do things this way. Instead, the final choice for each phone is determined by a combination of bottom-up signal processing and a statistical model of words and short word sequences. The methods are similar to the HMMs that we'll see soon for part of speech tagging.
If you have seen live transcripts of speeches (e.g. Obama's 2018 speech at UIUC) you'll know that there is still a significant error rate. This seems to be true whether they are produced by computers, humans, or (most likely) the two in collaboration. Highly-accurate systems (e.g. dictation) depend on knowing a lot about the speaker (how they normally pronounce words) and/or their acoustic environment (e.g. background noise) and/or what they will be talking about
A major challenge for speech recognition is that actual pronunciations of words frequently differ from their dictionary pronunciations. For example,
This kind of "phonological" change is part of the natural evolution of languages and dialects. Spelling conventions often reflect an older version of the language. Also, spelling systems often try to strike a middle ground among diverse dialects, so that written documents can be shared. The same is true, albeit to a lesser extent, of the pronunciations in dictionaries. These sound changes make it much harder to turn sequences of phones into words.
As we saw in the Naive Bayes lectures, different sorts of cleaning are required to make a clean stream of words from typical written text. We may also need to do similar post-processing to a speech recognizer's output. For example, the recognizer may be configured to transcribe into a sequence of short words (e.g. "base", "ball", "computer", "science") even when they form a tight meaning unit ("baseball" or "computer science"). Recognizers also faithfully reproduce disfluencies from the speaker (e.g. "um") and backchannels (e.g. "uh huh") from the listener. We may wish to remove these before later processing.