Before looking at these hints, do two things:
Read the general information on the MP main page and the syllabus page. Notice that this is an individual MP.
As early as possible, test that your python and pygame environment are working. We don't want to be solving installation problems close to the deadline.
Make gradescope submissions early and often. Although you can (and should) do many tests on your local machine, it's important to periodically check that your code also works on the autograder.
If you are new to python, notice that python dictionaries work extremely well. You'll want to use them frequently, even in places (e.g. storing (x,y) positions) where you might use an array in languages like C(++). See examples in the Python manual. A "defaultdict" is a variant dictionary type that supplies a default value for keys that haven't been explicitly given one.
When you write your code, use only standard python libraries. That is, modules that you can import without having to explicitly install an extension. The only exceptions are numpy and pygame. And you don't actually need numpy to do this MP.
Use good coding style, e.g. sensible variable names, functions that aren't too long, comments. This will make it easier for you to find bugs. Also, if we find your code hard to read, we will not help you find bugs in it.
Notice that the mazes are simple ASCII files. So you can make extra test examples using your favorite plaintext editor.
Descriptions of search methods tend to focus on the queue that's controlling the search. However, you also need some additional datastructures to implement these algorithms. Suppose that we are using A* to search this graph, with A as our starting location.
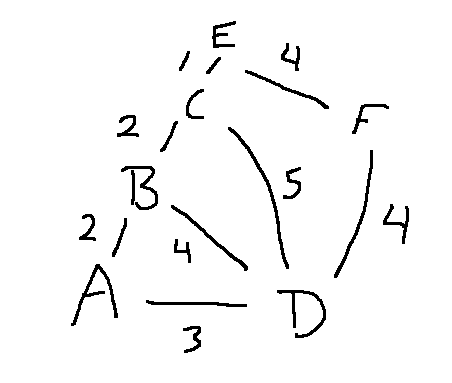
In your maze search, adjacent locations are always one unit apart. However, it's easier to understand the method using a graph with fewer locations but variable distances. In this example, a state is the same as a location.
In A*, the function g(S) returns the distance from the start state to state S. Here are some g values for our sample maze.
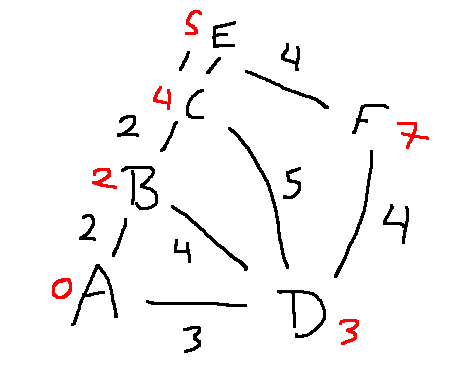
You'll need to keep a table of g values to consult as your A* search runs.
For each state, you need to keep a backpointer to the previous state on the best path from the start state. Here are the backpointers for this graph:
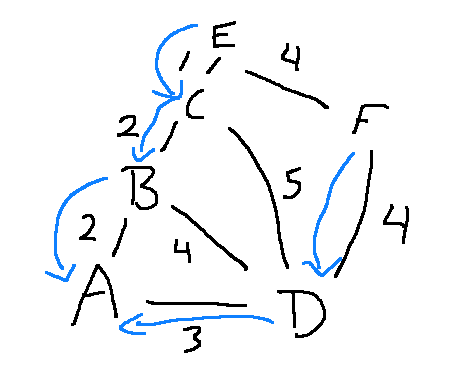
Suppose that our goal was location E. We can reconstruct the best path from A to E by following the backpointers: E points to C, C points to B, B points to A.
When your search reaches a state X that it has seen before, you need to check whether the new path to X has a smaller g value. If so, you need to update both the g value and the backpointer for X.
In the above example, each state was a named location (e.g. E). For this MP, your states will need to be structured objects. Obviously a state for our maze search needs to contain an (x,y) position. However, when you look ahead to the later parts of the MP, each state will also need to contain a list of waypoints. You cannot build correctly-working code for the later parts if your states contain only (x,y) positions.
Python offers several different ways to group several values into a single object, e.g. lists, tuples, classes, dataclasses. You can use the approach you find most comfortable. However, make sure it is easy to see which component of the state you are setting or retrieving. If your approach doesn't provide named accessors, e.g. you are using a tuple, use comments and good variable names to make it clear what lives in (say) position 3. Otherwise you're likely to make errors involving retrieving or setting the wrong component value and we'll find your code very difficult to decipher.
BFS and A* are very similar except for how the queue is managed. BFS uses a FIFO (first in, first out) queue. A* requires a priority queue. Python has built-in support for both. See the MP instructions.
Make sure that you have a clear understanding of when to return from your search loop. BFS can return as soon as it reaches a goal state. When A* first finds a goal state (as the neighbor of some other state), it must push that goal state back onto the queue. Your code should return only when a goal state is popped off the queue.
In some data structures classes, it is common practice to search the whole space (empty the queue) before returning the result. This is a very bad idea in AI search, because the search space may be very large or even infinite.
Suppose that you need to move the robot (R) through multiple waypoints. It's tempting to use the following "greedy" method. You search for the closest waypoint. Then you launch a new search from that waypoint to find the next waypoint. And you keep going, each time looking for the nearest individual waypoint. So the top level of your code is a loop that repeatedly calls your search method (e.g. BFS or A*).
Greedy search does not always return optimal paths. For example, consider the example below. (The numbers are x coordinates.)
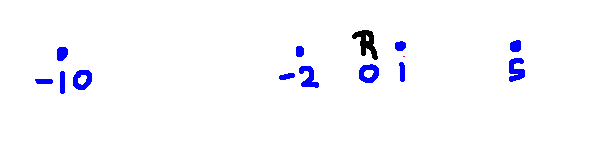
The greedy strategy will produce this path:
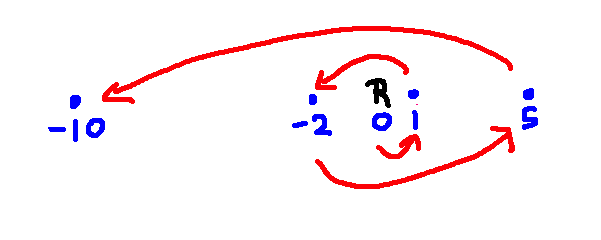
You should be able to find a much shorter path that goes through all the waypoints.
Do not use greedy search on this MP, except possibly for the last (suboptimal) part. The top level of your code should be a single search loop (e.g. A*). Use the MST heuristic described in the MP instructions.