
a real-world trellis (supporting a passionfruit vine)
Hidden Markov Models are used in a wide range of applications. They are similar to Bayes Nets (both being types of "Graphical Models"). We'll see them in the context Part of Speech tagging. Uses in other applications (e.g. speech) look very similar.
We saw part-of-speech (POS) tagging in a previous lecture. Recall that we start with a sequence of words. The tagging algorithm needs to decorate each word with a part-of-speech tag. Here's an example:
INPUT: Northern liberals are the chief supporters of civil rights and of integration. They have also led the nation in the direction of a welfare state.
OUTPUT: Northern/jj liberals/nns are/ber the/at chief/jjs supporters/nns of/in civil/jj rights/nns and/cc of/in integration/nn ./. They/ppss have/hv also/rb led/vbn the/at nation/nn in/in the/at direction/nn of/in a/at welfare/nn state/nn ./.
Identifying a word's part of speech provides strong constraints on how later processing should treat the word. Or, viewed another way, the POS tags group together words that should be treated similarly in later processing. For example, in building parse trees, the POS tags povide direct information about the local syntactic structure, reducing the options that the parse must choose from.
Many early algorithms exploit POS tags directly (without building a parse tree) because the POS tag can help resolve ambiguities. For example, when translating, the noun "set" (i.e. collection) would be translated very differently from the verb "set" (i.e. put). The part of speech can distinguish words that are written the same but pronounced differently, such as:
POS tag sets vary in size, e.g. 87 in the Brown corpus down to 12 in the "universal" tag set from Petrov et all 2012 (Google research). Even when the number of tags is similar, different designers may choose to call out different linguistic distinctions.
| our MP | "Universal" | |
|---|---|---|
| NOUN | Noun | noun |
| PRON | Pronoun | pronoun |
| VERB | Verb | verb |
| MODAL | modal verb | |
| ADJ | Adj | adjective |
| DET | Det | determiner or article |
| PERIOD | . (just a period) | end of sentence punctuation |
| PUNCT | other punctuation | |
| NUM | Num | number |
| IN | Adp | preposition or postposition |
| PART | particle e.g. after verb, looks like a preposition) | |
| TO | infinitive marker | |
| ADV | Adv | adverb |
| Prt | sentence particle (e.g. "not") | |
| UH | [not clear what tag] | filler, exclamation |
| CONJ | Conj | conjunction |
| X | X | other |
Here's a more complex set of 36 tags from the
Penn Treebank tagset .
The larger tag sets are a mixed blessing. On the one hand, the
tagger must make finer distinctions when it chooses the tag.
On the other hand, a more specific tag provides more information
for tagging later words and also for subsequent processing (e.g. parsing).
Each word has several possible tags, with different probabilities.
For example, "can" appears using in several roles:
Some other words with multiple uses
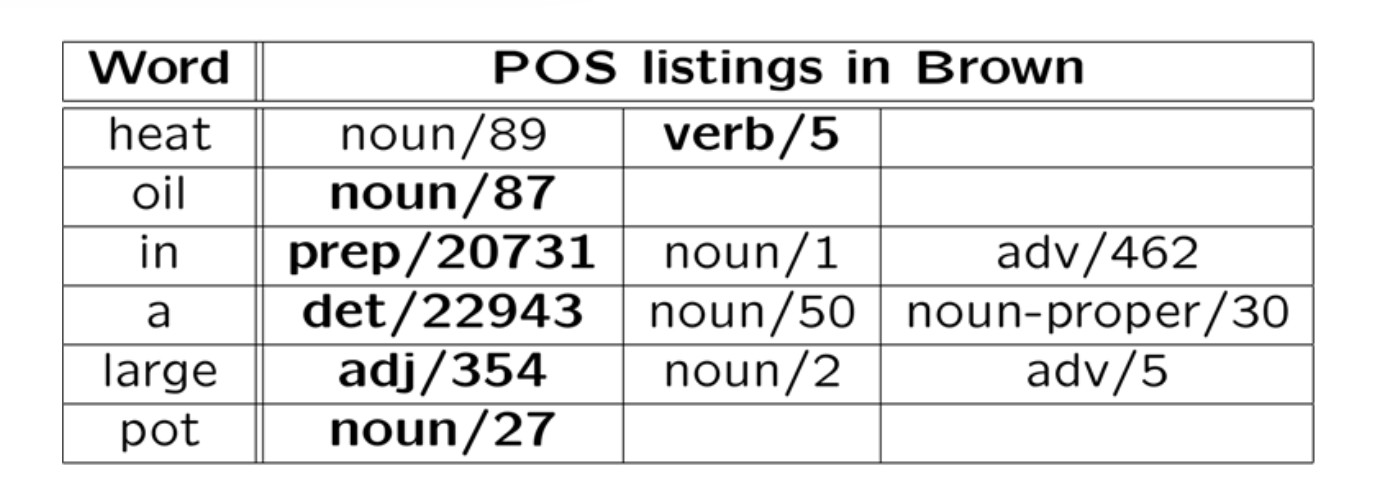
Consider the sentence "Heat oil in a large pot." The correct tag sequence
is "verb noun prep det adj noun". Here's the tags seen when training
on the Brown corpus.
Notice that
An example of that last would be "over" used as a noun (e.g. in cricket).
That is fairly common in British text but might never occur in a training corpus
from the US.
Most testing starts with a "baseline" algorithm, i.e. a simple
method that does do the job, but typically not very well. In this
case, our baseline algorithm might pick the most common tag for
each word, ignoring context. In the table above, the most common
tag for each word is shown in bold: it made one error out of six
words.
The test/development data will typically contain some words that weren't
seen in the training data. The baseline algorithm guesses that these
are nouns, since that's the most common tag for infrequent words. An
algorithm can figure this out by examining new words that appear in the
development set, or by examining the set of words that occur only once
in the training data ("hapax") words.
On larger tests, this baseline algorithm has an accuracy around 91%.
It's essential for a proposed new algorithm to beat the baseline. In
this case, that's not so easy because the baseline performance is
unusually high.
Tags and words
 (from Mitch Marcus)
(from Mitch Marcus)
Baseline algorithm