Game search uses a combination of two techniques:
Let's consider how to do adversarial search for a two player, deterministic, zero sum game. For the moment, let's suppose the game is simple enough that we can can build the whole game tree down to the bottom (leaf) level. Also suppose we expect our opponent to play optimally (or at least close to).
Traditionally we are called max and our opponent is called min. The following shows a (very shallow) game tree for some unspecified game. The final reward values for max are shown at the bottom (leaf) level.
max *
/ | \
/ | \
/ | \
min * * *
/ \ / | \ / \
max * * * * * * *
/|\ |\ /\ /\ /\ |\ /\
4 2 7 3 1 5 8 2 9 5 6 1 2 3 5
Minimax search propagates values up the tree, level by level, as follows:
In our example, at the first level from the bottom, it's max's move. So he picks the highest of the available values:
max *
/ | \
/ | \
/ | \
min * * *
/ \ / | \ / \
max 7 3 8 9 6 2 5
/|\ |\ /\ /\ /\ |\ /\
4 2 7 3 1 5 8 2 9 5 6 1 2 3 5
At the next level (moving upwards) it's min's turn. Min gains when we lose, so he picks the smallest available value:
max *
/ | \
/ | \
/ | \
min 3 6 2
/ \ / | \ / \
max 7 3 8 9 6 2 5
/|\ |\ /\ /\ /\ |\ /\
4 2 7 3 1 5 8 2 9 5 6 1 2 3 5
The top level is max's move, so he again picks the largest value. The double hash signs (##) show the sequence of moves that will be chosen, if both players play optimally.
max 6
/ ## \
/ ## \
/ ## \
min 3 / 6 ## 2
/ \ / | ## / \
max 7 3 8 9 6 2 5
/|\ |\ /\ /\ / ## |\ /\
4 2 7 3 1 5 8 2 9 5 6 1 2 3 5
This procedure is called "minimax" and is optimal against an optimal opponent. Usually our best choice even against suboptimal opponents unless we have special insight into the ways in which they are likely to play badly.
Minimax search extends to cases where we have more than two players and/or the game is not zero sum. In the fully general case, each node at the bottom contains a tuple of reward values (one per player). At each level/ply, the appropriate player choose the tuple that maximizes their reward. The chosen tuples propagate upwards in the tree, as shown below.
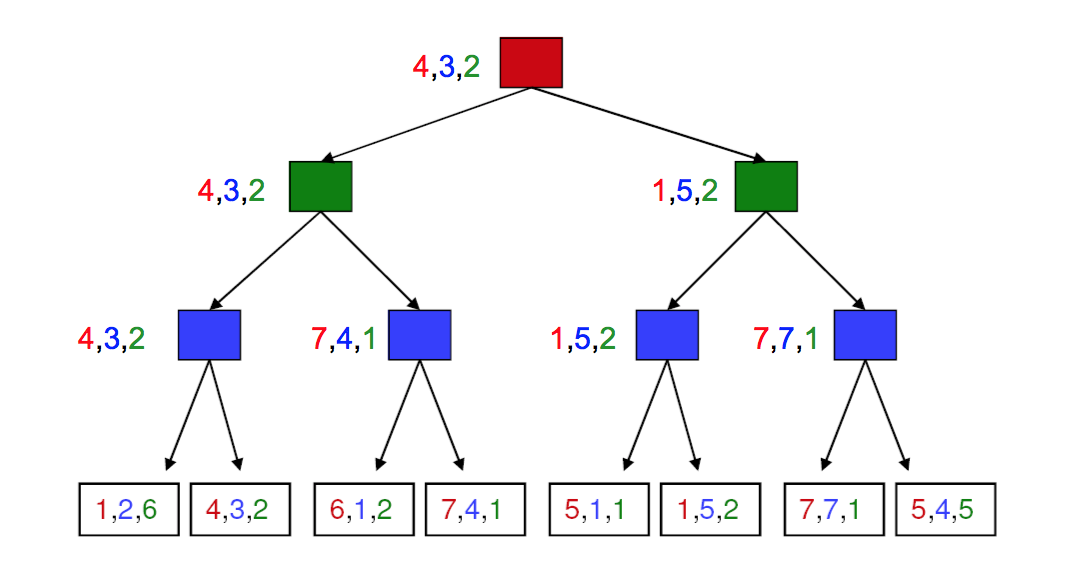
For more complex games, we won't have the time/memory required to search the entire game tree. So we'll need to cut off search at some chosen depth. In this case, we heuristically evaluate the game configurations in the bottom level, trying to guess how good they will prove. We then use minimax to propagate values up to the top of the tree and decide what move we'll make.
As play progresses, we'll know exactly what moves have been taken near the top of the tree. Therefore, we'll be able to expand nodes further and further down the game tree. When we see the final result of the game, we can use that information to refine our evaluations of the intermediate nodes, to improve performance in future games.
Here's a simple way to evaluate positions for tic-tac-toe. At the start of the game, there are 8 ways to place a line of three tokens. As play progresses, some of these are no longer available to one or both players. So we can evaluate the state by
f(state) = [number of lines open to us] - [number of lines open to opponent]
The figure below shows the evaluations for early parts of the game tree:
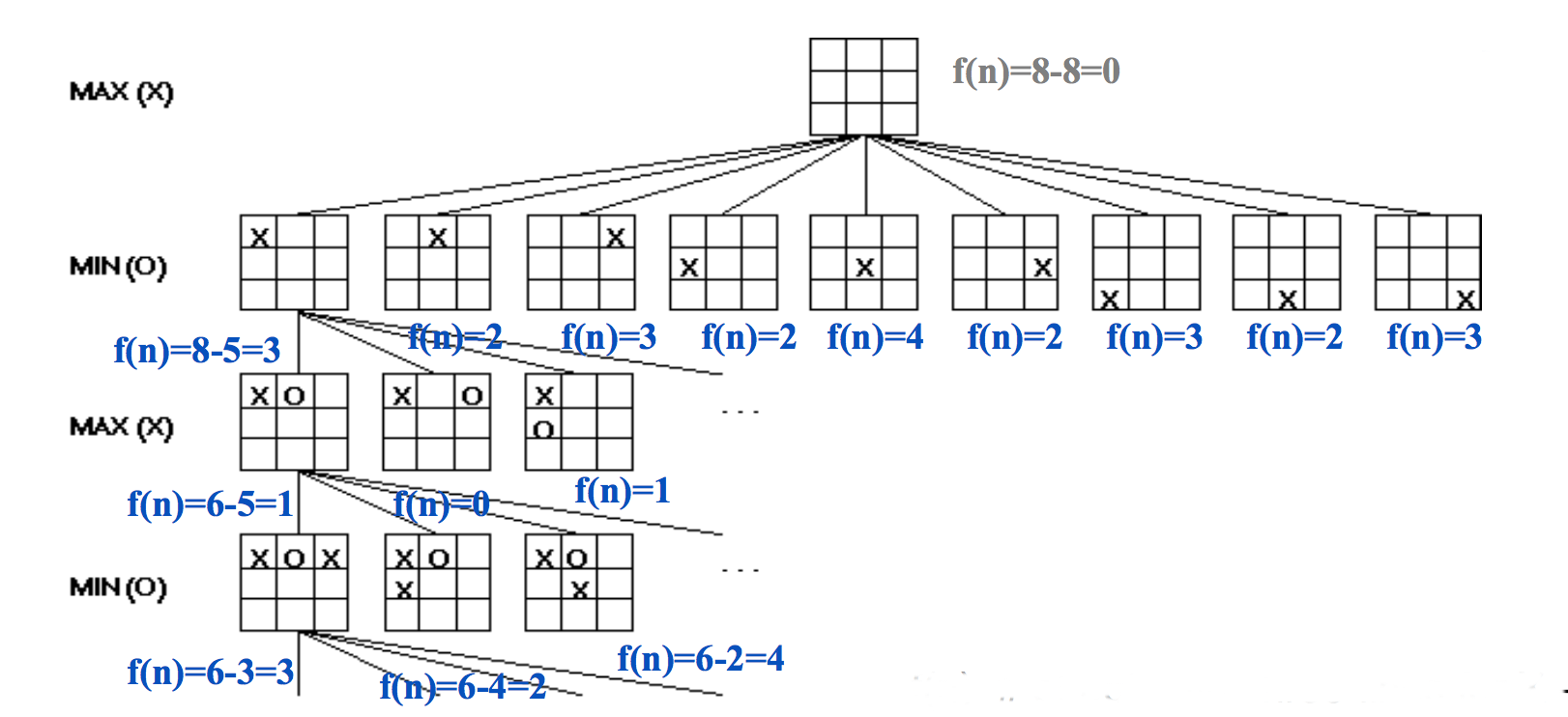
(from Mitch Marcus again)
Evaluations of chess positions dates back to a simple proposal by Alan Turing. In this method, we give a point value to each piece, add up the point values, and consider the difference between our point sum and that of our opponent. Appropriate point values would be
We can do a lot better by considering "positional" features, e.g. whether a piece is being threatened, who has control over the center. A weighted sum of these feature values would be used to evaluate the position. The Deep Blue chess program has over 8000 positional features.
More generally, evaluating a game configuration usually involves a weighted sum of features. In early systems, the features were hand-crafted using expert domain knowledge. The weighting would be learned from databases of played games and/or by playing the algorithm against itself. (Playing against humans is also useful, but can't be done nearly as many times.) In more recent systems, both the features and the weighting may be replaced by a deep neural net.
Something really interesting might happen just after the cutoff depth. This is called the "horizon effect." We can't completely stop this from happening. However, we can heuristically choose to stop search somewhat above/below the target depth rather than applying the cutoff rigidly. Some heuristics include:
Two other optimizations are common: