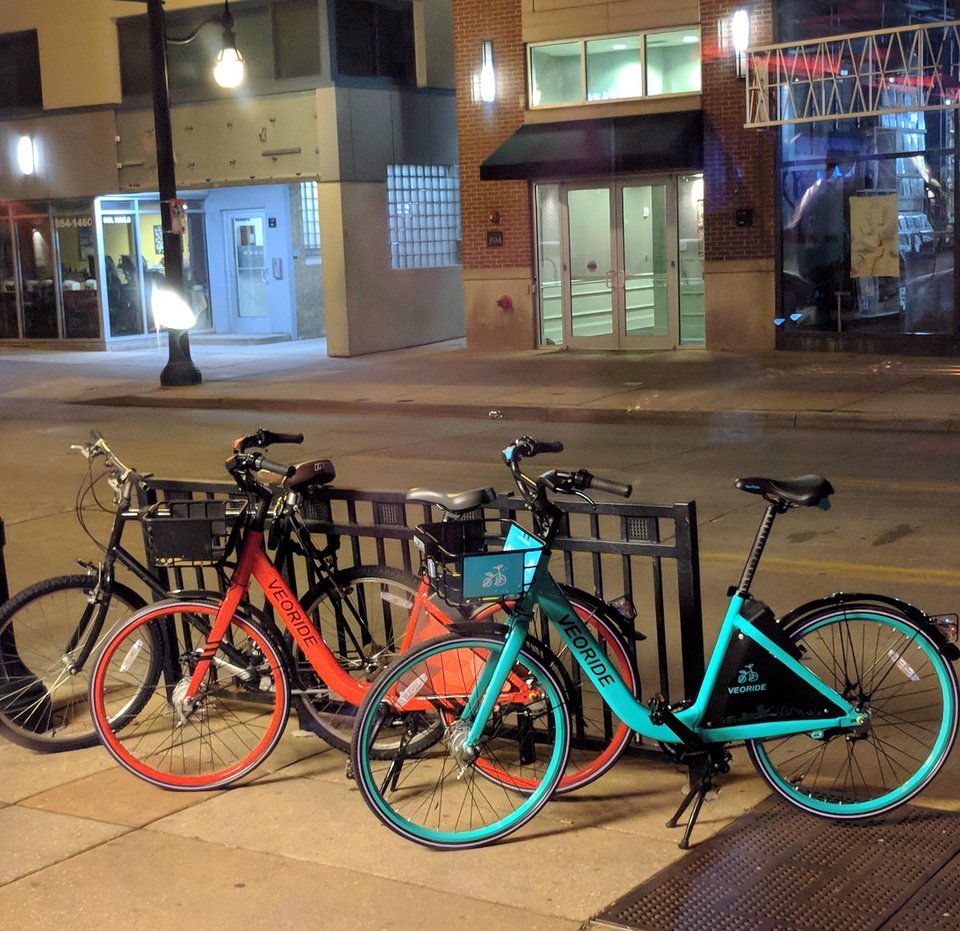 Red and teal veoride bikes from
/u/civicsquid reddit post
Red and teal veoride bikes from
/u/civicsquid reddit post
Suppose we are building a more complete bike recognition system. It might observe (e.g. with its camera) features like:
How do we combine these types of evidence into one decision about whether the bike is a veoride?
As we saw earlier, a large number of parameters would be required to model all of the \(2^n\) interactions between n variables. The Naive Bayes algorithm reduces the number of parameters to O(n) by making assumptions about how the variables interact,
Remember that two events A and B are independent iff
P(A,B) = P(A) * P(B)
Sadly, independence rarely holds. A more useful notion is conditional independence. That is, are two variables independent when we're in some limited context. Formally, two events A and B are conditionally independent given event C if and only if
P(A, B | C) = P(A|C) * P(B|C)
Conditional independence is also unlikely to hold exactly, but it is a sensible approximation in many modelling problems. For example, having a music stand is highly correlated with owning a violin. However, we may be able to treat the two as independent (without too much modelling error) in the context where the owner is known to be a musician.
The definiton of conditional independence is equivalent to either of the following equations:
P(A | B,C) = P(A | C)
P(B | A,C) = P(B | C)
It's a useful exercise to prove that this is true, because it will help you become familiar with the definitions and notation.
Suppose we're observing two types of evidence A and B related to cause C. So we have
P(C | A,B) \( \propto \) P(A,B | C) * P(C)
Suppose that A and B are conditionally independent given C. Then
P(A, B | C) = P(A|C) * P(B|C)
Substituting, we get
P(C | A,B) \( \propto \) P(A|C) * P(B|C) * P(C)
This model generalizes in the obvious way when we have more than two types of evidence to observe. Suppose our cause C has n types of evidence, i.e. random variables \( E_1,...,E_n \). Then we have
\( P(C | E_1,...E_n) \ \propto\ P(E_1|C) * ....* P(E_n|C) * P(C) \ = \ P(C) * \prod_{k=1}^n P(E_k|C) \)
So we can estimate the relationship to the cause separately for each type of evidence, then combine these pieces of information to get our MAP estimate. This means we don't have to estimate (i.e. from observational data) as many numbers. For n variables, a naive Bayes model has only O(n) parameters to estimate, whereas the full joint distribution has \(2^n\) parameters.