Classifier systems often have several stages. "Deep" models typically have more distinct layers. Each layer in a deep model does a simpler task and the representation type more changes gradually from layer to layer.
| speech recognizer | object identification | scene reconstruction | parsing | word meaning | |
|---|---|---|---|---|---|
| raw input | waveform | image | images | text | text |
| low-level features | MFCC features | edges, colors | corners, SIFT features | stem, suffixes word bigrams |
word neighbors |
| low-level labels | phone probabilities | local object ID | raw matchpoints | POS tags | word embeddings |
| output labels | word sequence | image description | scene geometry | parse tree | word classes |
Representations for the raw input objects (or sometimes the low-level features) have a large number of bits. E.g. a color image with 1000x1000 pixels, each containing three color values. Early processing often tries to reduce the dimensionality by picking out a smaller set of "most important" dimensions. This may be accomplished by linear algebra (e.g. principal components analysis) or by classifiers (e.g. word embedding algorithms).
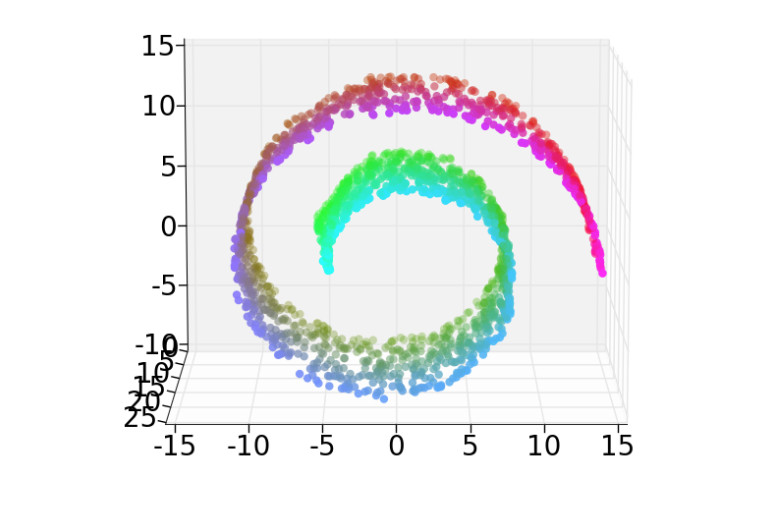
When the data is known to live on a subset of lower dimension, vectors may be mapped onto this subset by so-called "manifold learning" algorithms. For example, color is used to enclose class (output label). Distance along the spiral correctly encodes class similarity. Straight-line distance in 3D does the wrong thing: some red-green pairs of points are closer than some red-red pairs.
There are two basic approaches to each stage of processing:
Many real systems are a mix of the two. A likely architecture for a speech recognizer (e.g. the Kaldi system) would start by converting the raw signal to MFCC features, then use a neural net to identify phones, then use an HMM-type decoder to extract the most likely word sequence.
There are three basic types of classifiers with learned parameters. We've already seen the first type and we're about to move onto the other three
Classifiers typically have a number of overt variables that can be manipulated to produce the best outputs. These fall into two types:
Researchers also tune the structure of the model.
It is now common to use automated scripts to tune hyperparameters and some aspects of the model structure. Tuning these additional values is a big reason why state-of-the-art neural nets are so expensive to tune. All of these tunable values should be considered when assessing whether the model could potentially be over-fit to the training/development data, and therefore might not generalize well to slightly different test data.
Training and testing can be interleaved to varying extents:
Incremental training is typically used by algorithms that must interact with the world before they have finished learning. E.g. children need to interact with their parents from birth, long before their language skills are fully mature. Sometimes interaction is to get their training data. E.g. a video game player may need to play experimental games. Incremental training algorithms are typically evaluated based on their performance towards the end of training.
Traditionally, most classifiers used "supervised" training. That is, someone gives the learning algorithm a set of training examples, together with correct ("gold") output for each one. This is very convenient, and it is the setting in which we'll learn classifier techniques. But this only works when you have enough labelled training data. Usually the amount of training data is inadequate, because manual annotations are very slow to produce.
Moreover, labelled data is always noisy. Algorithms must be robust to annotation mistakes. It may be impossible to reach 100% accuracy because the gold standard answers aren't entirely correct.
Finally, large quantities of correct answers may be available only for the system as a whole, not for individual layers. Marking up correct answers for intermediate layers frequently requires expert knowledge, so cannot easily be farmed out to students or internet workers.
Researchers have a used a number of methods to work around lack of explicit labelled training data. For example, current neural net software lets us train the entire multi-layer as a unit. Then we need correct outputs only for the final layer. This type of training optimizes the early layers only for this specific task. However, it may be possible to quickly adapt this "pre-trained" layer for use in another task, using only a modest amount of new training data for the new task.
For example, the image colorization algorithm shown below learns how to add color to black and white images. The features it exploits in the monochrome images can also (as it turns out) be used for object tracking.


from Zhang, Isola, Efros
Colorful Image Colorization
For this colorization task, the training pairs were produced by removing color from
color pictures. That is, we subtracted information and learned to restore it.
This trick for producing training pairs has been used elsewhere. For example, the
BERT system trains natural language models by masking off words in training sentences,
and learning to predict what they were. Similarly, the pictures below illustrate
that we can learn to fill in missing image content, by creating training images with
part of the content masked off.

from
Deepak Pathak et al
Another approach is self-supervision, in which the learner experiments with the world to find out new information. Examples of self-supervision include
The main challenge for self-supervised methods is designing ways for a robot to interact with a real, or at least realistic, world without making it too easy for the robot to break things, injury itself, or hurt people.
"Semi-supervised" algorithms extract patterns from unannotated data, combining this with limited amounts of annotated data. For example, a translation algorithm needs some parallel data from the two languages to create rough translations. The output can be made more fluent by using unannotated data to learn more about what word patterns are/aren't appropriate for the output language. Similarly, we can take observed pauses in speech and extrapolate the full set of locations where it is appropriate to pause (i.e. word boundaries).
"Unsupervised" algorithms extract patterns entirely from unannotated data. These are much less common than semi-supervised methods. Sometimes so-called unsupervised methos actually have some implicit supervision (e.g. sentence boundaries for a parsing algorithm). Sometimes they are based on very strong theoretical assumptions about how the input must be structured.