Hidden Markov Models are used in a wide range of applications. They are similar to Bayes Nets (both being types of "Graphical Models"). We'll see them in the context Part of Speech tagging. Uses in other applications (e.g. speech) look very similar.
Recall: in part of speech tagging, we start with a sequence of words, divided into sentences:
Northern liberals are the chief supporters of civil rights and of integration. They have also led the nation in the direction of a welfare state.
The tagging algorithm needs to decorate each word with a part-of-speech (POS) tag, producing an output like this:
Northern/jj liberals/nns are/ber the/at chief/jjs supporters/nns of/in civil/jj rights/nns and/cc of/in integration/nn ./. They/ppss have/hv also/rb led/vbn the/at nation/nn in/in the/at direction/nn of/in a/at welfare/nn state/nn ./.
Capture local syntactic configuration, to reduce complexity of later parsing
Early algorithms can exploit the tag information directly
"Universal" tag set from Petrov et all 2012 (Google research).
Noun (noun)
Verb (verb)
Adj (adjective)
Adv (adverb)
Pron (pronoun)
Det (determiner or article)
Adp (preposition or postposition)
Num (numeral)
Conj (conjunction)
Prt (particle)
'.' (punctuation mark)
X (other)
The X tag seems to be a dumping ground for categories that they found hard to deal with, e.g. numeral classifiers.
Tag sets can get much more complex, e.g. 36 tags in the Penn Treebank tagset .
Each word has several possible tags, with different probabilities.
For example, "can" appears using in several roles:
Some other words with multiple uses
Consider the sentence "Heat oil in a large pot." The correct tag sequence is "verb noun prep det adj noun". Here's the tags seen when training on the Brown corpus.
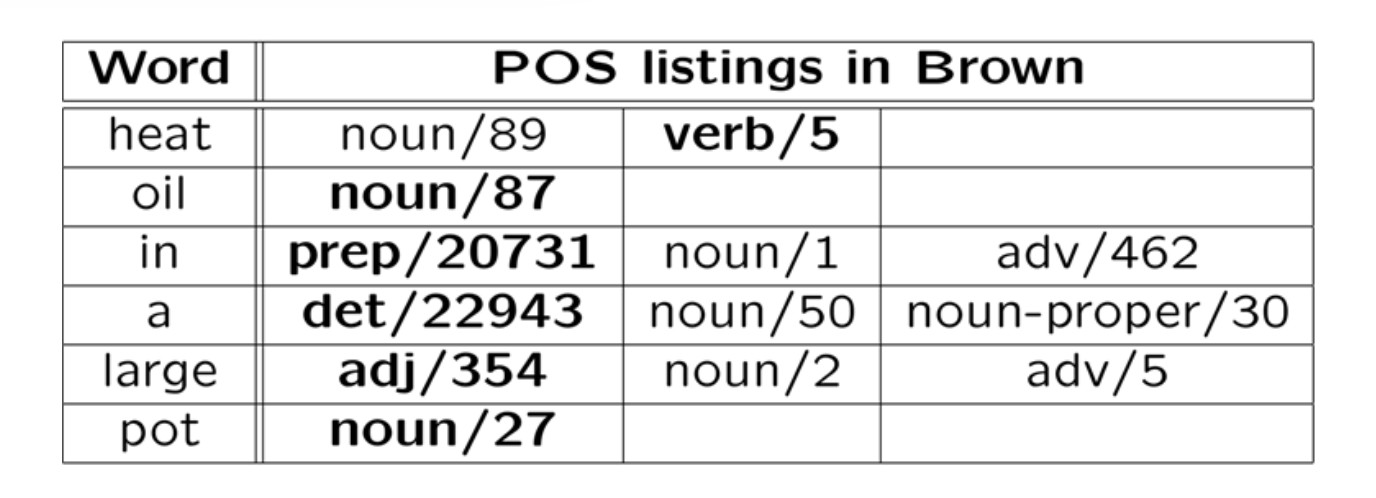 (from Mitch Marcus)
(from Mitch Marcus)
Notice that
Most testing starts with a "baseline" algorithm, i.e. a simple method that does do the job, but typically not very well. In this case, our baseline algorithm might pick the most common tag for each word, ignoring context. In the table above, the most common tag for each word is shown in bold: it made one error out of six words.
The test/development data will typically contain some words that weren't seen in the training data. The baseline algorithm guesses that these are nouns, since that's the most common tag for infrequent words. An algorithm can figure this out by examining new words that appear in the development set, or by examining the set of words that occur only once in the training data ("hapax") words.
On larger tests, this baseline algorithm has an accuracy around 91%. It's essential for a proposed new algorithm to beat the baseline. In this case, that's not so easy because the baseline performance is unusually high.
Suppose that W is our input word sequence (e.g. a sentence) and T is an input tag sequence. That is
W=w1,w2,…wn
T=t1,t2,…tn
Our goal is to find a tag sequence T that maximizes P(T | W). Using Bayes rule, this is equivalent to maximizing P(W∣T)∗P(T)/P(W) And this is equivalent to maximizing P(W∣T)∗P(T) because P(W) doesn't depend on T.
So we need to estimate P(W | T) and P(T) for one fixed word sequence W but for all choices for the tag sequenceT.
Obviously we can't directly measure the probability of an entire sentence given a similarly long tag sequence. Using (say) the Brown corpus, we can get reasonable estimates for
If we have enough tagged data, we can also estimate tag trigrams. Tagged data is hard to get in quantity, because human intervention is needed for checking and correction.
To simplify the problem, we make "Markov assumptions." A Markov assumption is that the value of interest depends only on a short window of context. For example, we might assume that the probability of the next word depends only on the two previous words. You'll often see "Markov assumption" defined to allow only a single item of context. However, short finite contexts can easily be simulated using one-item contexts.
For POS tagging, we make two Markov assumptions. For each position k:
P(wk) depends only on P(tk)
P(tk) depends only on P(tk−1
Therefore
P(W∣T)=∏ni=1P(wi∣ti)
P(T)=P(t1|START)∗∏ni=1P(tk∣tk−1)
where P(t1|START) is the probability of tag t1 at the start of a sentence.
Like Bayes nets, HMMs are a type of graphical model and so we can use similar pictures to visualize the statistical dependencies:

In this case, we have a sequence of tags at the top. Each tag depends only on the previous tag. Each word (bottom row) depends only on the corresonding tag.