 from Berkeley CS 188 slides
from Berkeley CS 188 slides
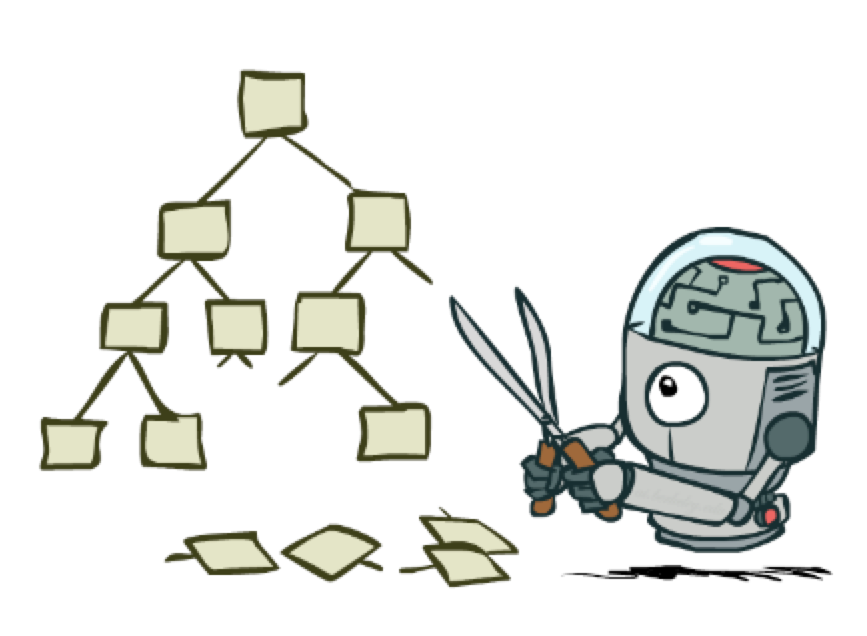
Each tree node represents a game state.
As imagined by a theoretician, each time we need to move:
Minimax propagates values up a tree as follows:
But we're actually doing a recursive depth-first search, so the code for each move actually looks like:
Suppose that move(node,action) is the state/node that results from that action. That is, move(n,a) produces one of the children of n.
The two functions min-value and max-value return the utility of their input node/state, handling the cases of (respectively) a min node or a max node in the tree.
max-value (node)
- if node is a leaf, return its value.
- else
- rv = -inf
- for each action a
- rv = max(rv, min-value(move(node,a))
- return rv
min-value (node)
- if node is a leaf, return its value.
- else
- rv = +inf
- for each action a
- rv = min(rv, max-value(move(node,a))
- return rv
Notice that a game player needs his next move, not the value for the top node of the tree (aka the current game state). So the actual top-level function would
But this is easy, so we'll concentrate on compute values for nodes in game trees.
How do we make this process more effective?
Idea: we can often compute the utility of the root without examining all the nodes in the game tree.
Once we've seen some of the lefthand children of a node, this gives us a preliminary value for that node. For a max node, this is a lower bound on the value at the node. For a min node, this gives us an upper bound. Therefore, as we start to look at additional children, we can abandon the exploration once it becomes clear that the new child can't beat the value that we're currently holding.
Look through this pruning example from Diane Litman (U. Pitt).
As you can see from this example, this strategy can greatly reduce the amount of the tree we have to explore. Remember that we're building the game tree dynamically as we do depth-first search, so "don't have to explore" means that we never even allocate those nodes of the tree.
The variables \(\alpha\) and \(\beta\) are used to keep track of the current upper and lower bounds, as we do the depth-first search.
Suppose that v is the value of some node we're looking at. If the path to this node is still viable, we must have
\(\alpha \le v \le \beta\)
We pass alpha and beta down in our depth-first search, returning prematurely when
To see the values \(\alpha\) and \(\beta\) in action, experiment with this alpha-beta pruning animation (Berkeley Data structures, Fall 2014, Paul Hilfinger and Josh Hug).
Here's the pseudo-code for minimax with alpha-beta pruning. The changes from normal minimax are shown in red. Inside the inner loop for max-value, notice that rv gradually increases. The function returns prematurely if rv reaches beta.
max-value (node, alpha, beta )
- if node is a leaf, return its value.
- else
- rv = -inf
- for each action a
- rv = max(rv, min-value(move(node,a), alpha, beta )
- if rv >= beta, return rv
- else alpha = max(alpha, rv)
- return rv
min-value (node, alpha, beta )
- if node is a leaf, return its value.
- else
- rv = +inf
- for each action a
- rv = min(rv, max-value(move(node,a), alpha, beta )
- if rv <= alpha, return rv
- else beta = min(beta,rv)
- return rv
Notice that the left-to-right order of nodes matters to the performance of alpha-beta pruning. See this example (from Mitch Marcus (U. Penn), adapted from Rick Lathrop (USC)). Remember that the tree is built dynamically, so this left-to-right ordering is determined by the order in which we consider the various possible actions (moves in the game).
Suppose that we have b moves in each game state (i.e. branching factor b), and our tree has height m. Then standard minimax examines \(O(b^m) \) nodes. If we visit the nodes in the optimal order, alpha-beta pruning will reduce the number of nodes searched to \(O(b^{m/2}) \). If we visit the nodes in random order, we'll examine \(O(b^{3m/4}) \) on average.
Obviously, we can't magically arrange to have the nodes in exactly the right order. However, heuristic ordering of actions can get close to the optimal O(b^{m/2}) in practice. For example, a good heuristic order for chess examines possible moves in the following order:
Something really interesting might happen just after the cutoff depth. This is called the "horizon effect." We can't completely stop this from happening. However, we can heuristically choose to stop search somewhat above/below the target depth rather than applying the cutoff rigidly. Some heuristics include:
Two other optimizations are common:
Boston Dynamics Robot does parkour (from NBC).