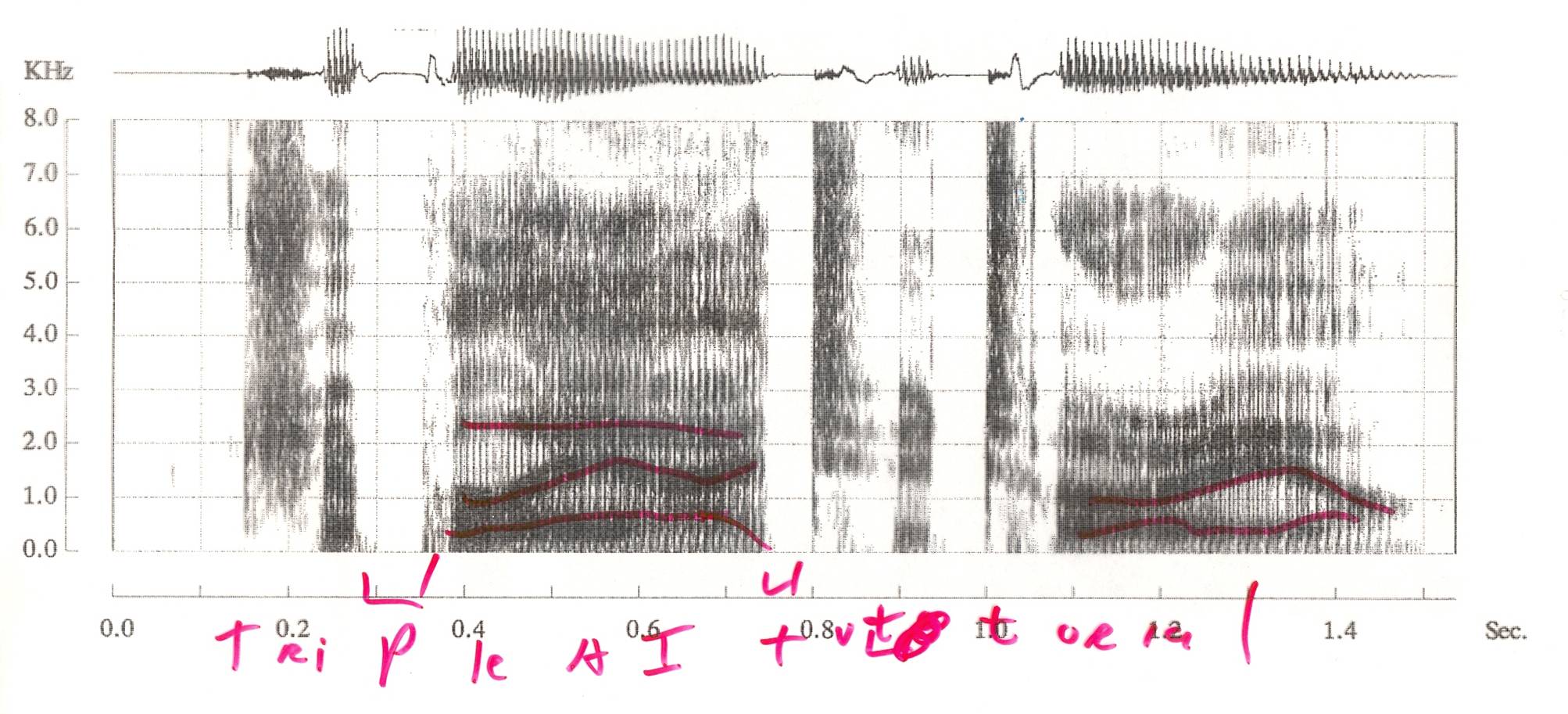
Speech waveform (top) and spectrogram (bottom) for "AAAI tutorial" (from Mitch Marcus). AAAI is usually pronounced "triple A I". Vowel formants are the dark bands marked in red.
Before we dive into specific natural language tasks, let's look at some end-to-end systems that have been constructed. These work with varying degrees of generality and robustness.
Interactive systems have been around since the early days of AI and computer games. For example:
These older systems used simplified text input. The computer's output seems to be sophisticated, but actually involves a limited set of generation rules stringing together canned text. Most of the sophistication is in the backend world model. This enables the systems to carry on a coherent dialog, something that is still a major challenge for current systems. For example, you'll get a sensible answer if you ask Google home a question like "How many calories in a banana?" However, it can't understand the follow-on "How about an orange?" because it processes each query separately.
Translation The input/output is usually text, but occasionally speech. Google translate is impressive, but can also fail catastrophically. A classic test is a circular translation: X to Y and then back to X. Google translate can still be made to fail by picking a lesser-common language (Zulu) and topic (making kimchi).
Transcription/captioning If you saw the live transcripts of Obama's recent speech at UIUC (probably a human/computer hybrid transcription), you'll know that there is still a significant error rate. Highly-accurate systems (e.g. dictation) depend on knowing a lot about the speaker (how they normally pronounce words) and/or their acoustic environment (e.g. background noise) and/or what they will be talking about (e.g. phone help lines).
Evaluating/correcting Everyone uses spelling correction (largely a solved problem). Useful upgrades (somewhat working) include detection of grammar errors, adding vowels or diacritics in language (e.g. Arabic) where they are often omitted. Speech recognition has been used for evaluating English fluency and children learning to read (e.g. aloud). This depends on very strong expectations about what the person will say.
Speech or natural language based HCI For example, speech-based airline reservations (a task that was popular historically in AI) or utility company help lines. Google had a recent demo of a computer assistant making a restaurant by phone. There have been demo systems for tutoring, e.g. physics.
Many of these systems depend on the fact that people will adapt their language when they know they are talking to a computer. It's often critical that the computer's responses not sound too sophisticated, so that the human doesn't over-estimate its capabilities. (This may have happened to you when attempting a foreign language, if you are good at mimicking pronunciation.) These systems often steer humans towards using certain words. E.g. when the computer suggests several alternatives ("Do you want to report an outage? pay a bill?") the human is likely to use similar words in their reponse.
Summarizing information Combining and selecting text from several stories, to produce a single short abstract. The user may read just the abstract, or decide to drill down and read some/all of the full stories. Google news is a good example of a robust summarization system.
Answering questions, providing information For example, "How do I make zucchini kimchi?" "Are tomatoes fruits?" Normally (e.g. google search) this uses very shallow processing: find documents that seem to be relevant and show extracts to the user. Deeper processing has usually been limited to focused domains, e.g. google's ability to summarize information for a business (address, opening hours, etc).
It's harder than you think to model human question answering, i.e. understand the meaning of the question, find the answer in your memorized knowledgebase, and then synthesize the answer text from a representation of its meaning. This is mostly confined to pilot systems, e.g. the ILEX system for providing information about museum exhibits.
Recognition is harder than generation. However, generation is not as easy as you might think.
The first "speech recognition" layer of processing turns speech (e.g. the waveform at the top of this page) into a sequence of phones (basic units of sound). We first process the waveform to bring out features important for recognition. The spectogram (bottom part of the figure) shows the energy at each frequency as a function of time, creating a human-friendly picture of the signal. Computer programs use something similar, but further processed into a small set of numerical features.
Each phone shows up in characteristic ways in the spectrogram. Stop consonants (t, p, ...) create a brief silence. Fricatives (e.g. s) have high-frequency random noise. Vowels and semi-vowels (e.g. n, r) have strong bands ("formants") at a small set of frequencies. The location of these bands and their changes over time tell you which vowel or semi-vowel it is.
Models of human language understanding typically assume that a first stage that produces a reasonably accurate sequence of phones. The sequence of phones must then be segmented into a sequence of works or "morphemes." A morpheme is a meaning unit that forms part of a word, e.g. a stem or a prefix or suffix. For example:
unanswerable --> un-answer-able
preconditions --> pre-condition-s
If we're segmenting phone sequences into words, the process might look like this, where # marks a literal pause in speech (e.g. the speaker taking a breath).
INPUT: ohlThikidsinner # ahrpiyp@lThA?HAvkids # ohrThADurHAviynqkids
OUTPUT: ohl Thi kids inner # ahr piyp@l ThA? HAv kids # ohr ThADur HAviynq kids
In standard written English, this would be "all the kids in there # are people that have kids # or that are having kids".
Systems starting from textual input may face a similar segmentation problem. Some writing systems do not put spaces between words. Also, words in some languages can get extremely long, making it hard to do further processing unless they are (at least partly) subdivided into morphemes.
In the above example, notice that "in there" has fused together into "inner" with the "th" sound changing to become like the "n" preceding it. This kind of "phonological" sound change makes both speech recognition and word segmentation much harder.
The combination of signal processing challenges and phonological changes means that, in practice, current speech recognizers cannot actually transcribe speech into a sequence of phones without some broader-scale context. Most recognizers use a simple (ngram) model of words and word to correct the raw phone recognition and, therefore, produce word sequences directly. So the actual sequence of processing stages depends on the application and whether you're talking about production computer systems or models of human language understanding.
NLP systems may also have to fuse input units into larger ones. For example, speech reognition systems may be configured to transcribe into a sequence of short words (e.g. "base", "ball", "computer", "science") even when they form a tight meaning unit ("baseball" or "computer science"). This is a particularly important problem for writing systems such as Chinese. Consider this well-known sequence of two characters:
Zhōng + guó
Historically, this is two words ("middle" and "country") and the two characters appear in writing without overt indication that they form a unit. But they are, in fact, a single word meaning China. Grouping input sequences of characters into similar meaning units is an important first step in processing Chinese text.