5. Problem Description and Implementation Overview:
In this MP, we will be creating a search engine that indexes the dumps of Wikipedia that are stored in /class/cs423/MP4/data in the EWS machines. There are two xml files that need to be indexed. Since you only need the read access to these files, you do not have to copy these files to your home directory. In case you want to use different Hadoop set-up / machine, you can download the data files from Box (Compressed 600MB).
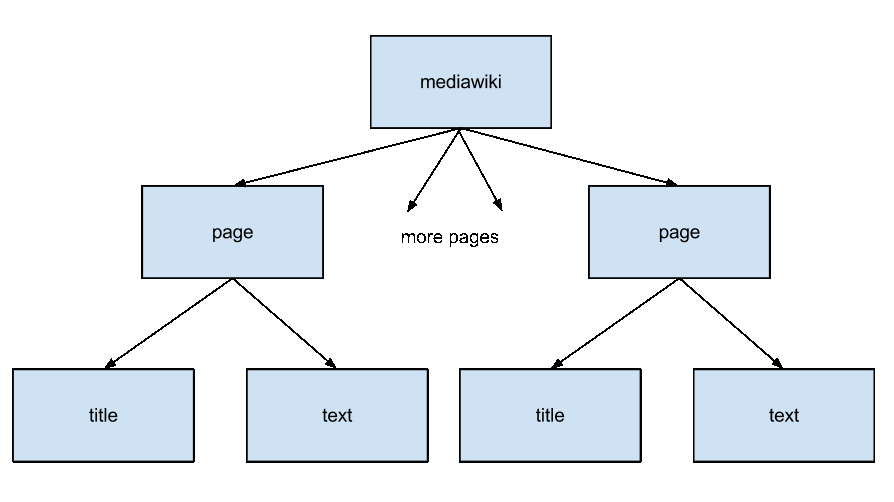
– Parsing: In the first step, the xml files need to be parsed into individual articles. The DOM structure of each of the xml files is mediawiki->[page->title, text]+. It might be advisable to split the xml files into numbered documents for easy reference, each containing one wikipedia article, defined by a title and the associated text. There are a number of libraries in different languages that can help you perform this task.
– Map/Reduce: During mapping, every single-worded token from each document (title + text) is read and is emitted as a (token, document id) pair. All tokens are converted to lower-case before emitting the pair.
The java code for tokenizing would be String[] tokens = line.toLowerCase().split("[^a-z]")
During reduction, we form the inverted index, i.e. create a table with single-worded tokens as the key, and the list of documents (with counts) it is present in as the value. Inverted Index
As an example, suppose we have the following three documents:
1: "Hello World"
2: "HELLO again"
3: "Goodbye cruel world, goodbye"
The (token, document id) pairs after map phase will be (hello, 1), (world, 1), (hello, 2), (again, 2), (goodbye, 3), (cruel, 3), (world, 3), (goodbye, 3).
The inverted document index would be as follows:
hello: (1 [1], 2 [1])
world: (1 [1], 3 [1])
again: (2 [1])
goodbye: (3 [2])
cruel: (3 [1])
Square brackets shows the term frequency of token in the documents. Remember that both the title and the text of the document need to be indexed in the case of the wiki dump. An example text element from the wiki dump is :
{{for|album of the same name|Octavarium (album)}}
{{Multiple issues|refimprove=May 2007|onesource=March 2009|cleanup=August 2007}}
{{Infobox song
| Name = Octavarium
| Cover =
| Format = [[Compact disc|CD]]
| Artist = [[Dream Theater]]
| Album = [[Octavarium (album)|Octavarium]]
| track_no = 8
| Recorded = 2005
| Genre = [[Progressive metal]], [[symphonic metal]], [[progressive rock]], [[ambient music]]
| Length = 24:00
| Label = [[Atlantic Records]]
| Writer = [[James LaBrie]], [[John Petrucci]], [[Mike Portnoy]]
| Composer = [[Dream Theater]]
| prev = "Sacrificed Sons"
| prev_no = 7
| Misc =
}}
'''Octavarium''' is a song by [[progressive metal]] band [[Dream Theater]], from the [[Octavarium (album)|album of the same name]].
The song starts with [[Jordan Rudess]] using his [[Continuum (instrument)|Haken Continuum]] and his [[lap steel guitar]], drawing references from [[Pink Floyd]]'s "[[Shine On You Crazy Diamond]]", [[Tangerine Dream]], [[Marty Friedman (guitarist)|Marty Friedman]]'s ''[[Scenes (album)|Scenes]]'', and [[Queen (band)|Queen]]'s "[[Innuendo (album)#Bijou|Bijou]]".
Just retrieve the text
{{for|album of the same name|Octavarium (album)}}
{{Multiple issues|refimprove=May 2007|onesource=March 2009|cleanup=August 2007}}
{{Infobox song
| Name = Octavarium
| Cover =
| Format = [[Compact disc|CD]]
| Artist = [[Dream Theater]]
| Album = [[Octavarium (album)|Octavarium]]
| track_no = 8
| Recorded = 2005
| Genre = [[Progressive metal]], [[symphonic metal]], [[progressive rock]], [[ambient music]]
| Length = 24:00
| Label = [[Atlantic Records]]
| Writer = [[James LaBrie]], [[John Petrucci]], [[Mike Portnoy]]
| Composer = [[Dream Theater]]
| prev = "Sacrificed Sons"
| prev_no = 7
| Misc =
}}
'''Octavarium''' is a song by [[progressive metal]] band [[Dream Theater]], from the [[Octavarium (album)|album of the same name]].
The song starts with [[Jordan Rudess]] using his [[Continuum (instrument)|Haken Continuum]] and his [[lap steel guitar]], drawing references from [[Pink Floyd]]'s "[[Shine On You Crazy Diamond]]", [[Tangerine Dream]], [[Marty Friedman (guitarist)|Marty Friedman]]'s ''[[Scenes (album)|Scenes]]'', and [[Queen (band)|Queen]]'s "[[Innuendo (album)#Bijou|Bijou]]".
and apply the tokenizer without any further cleaning of the text.
– Searching:Output this inverted index to disk and write a program that can load this inverted index and give results for single-word and multi-word token queries made by the user. For multi-word queries, you need to take intersection of document lists of individual tokens. The list of top ten documents ranked according to the metric below must be returned for each query made.
- Ranking: For any token, rank the list of documents it is found in using the term frequency (tf) , i.e. the document in which the term appears the most will be ranked the first, the document in which the term appears the second most number of times will be ranked second, and so on. The results for multi-word queries should be ranked according to the combined term frequency (tf) of the documents (after taking intersection).
The search results should be the titles of the relevant pages.
Example:
Search term = "Tennis"
Results:
1) 2008 US Open (tennis)
2) List of table tennis players
3) World Table Tennis Championships
4) 2008 ATP Tour
6. Demo:
Have a program which when given search terms will produce output as shown above in red. The pre-processing, and MapReduce computation should be performed beforehand and the necessary inverted index should be available for your demo program.