Optimization
Learning objectives
- Set up a problem as an optimization problem
- Use a method to find an approximation of the minimum
- Identify challenges in optimization
Minima of a function
Consider a function , and . The point is called the minimizer or minimum of if .
For the rest of this topic we try to find the minimizer of a function, as one can easily find the maximizer of a function by trying to find the minimizer of .
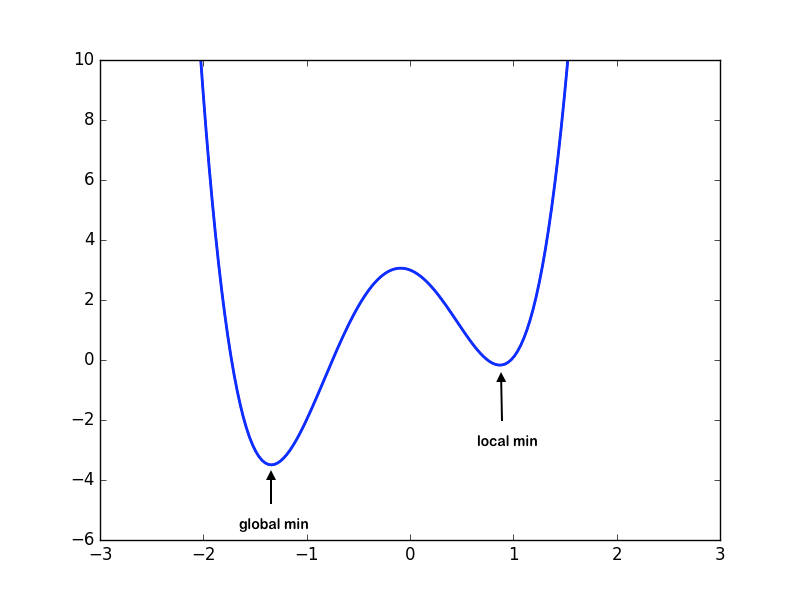
Local vs. Global Minima
Consider a domain , and .
-
Local Minima: is a local minimum if for all feasible in some neighborhood of .
-
Global Minima: is a global minimum if for all .
Note that it is easier to find the local minimum than the global minimum. Given a function, finding whether a global minimum exists over the domain is in itself a non-trivial problem. Hence, we will limit ourselves to finding the local minima of the function.
Criteria for 1-D Local Minima
In the case of 1-D optimization, we can tell if a point is a local minimum by considering the values of the derivatives. Specifically,
- (First-order) Necessary condition:
- (Second-order) Sufficient condition: and .
Example: Consider the function The first and second derivatives are as follows:
The critical points are tabulated as:
| \({x}\) | \({f'(x)}\) | \({f''(x)}\) | Characteristic |
|---|---|---|---|
| 3 | 0 | \(6\) | Local Minimum |
| 1 | 0 | \(-6\) | Local Maximum |
Looking at the table, we see that satisfies the sufficient condition for being a local minimum.
Criteria for N-D Local Minima
As we saw in 1-D, on extending that concept to dimensions we can tell if is a local minimum by the following conditions:
- Necessary condition: the gradient
- Sufficient condition: the gradient and the Hessian matrix is positive definite.
Definiton of Gradient and Hessian Matrix
Given we define the gradient function as:
Given we define the Hessian matrix as:
Unimodal
A function is unimodal on an interval means this function has a unique global minimum on that interval
A 1-dimensional function , is said to be unimodal if for all , with and as the minimizer:
- If
- If
Some examples of unimodal functions on an interval:
-
is unimodal on the interval
-
is not unimodal on because the global minimum is not unique. This is an example of a convex function that is not unimodal.
-
is not unimodal on . It has a unique minimum at but does not steadily decrease(i.e., monotonically decrease) as you move from to .
-
is not unimodal on the interval because it increases on .
In order to simplify, we will consider our objective function to be unimodal as it guarantees us a unique solution to the minimization problem.
Optimization Techniques in 1-D
Newton’s Method
We know that in order to find a local minimum we need to find the root of the derivative of the function. Inspired from Newton’s method for root-finding we define our iterative scheme as follows: This is equivalent to using Newton’s method for root finding to solve , so the method converges quadratically, provided that is sufficiently close to the local minimum.
For Newton’s method for optimization in 1-D, we evaluate and , so it requires 2 function evaluations per iteration.
Golden Section Search
Inspired by bisection for root finding, we define an interval reduction method for finding the minimum of a function. As in bisection where we reduce the interval such that the reduced interval always contains the root, in Golden Section Search we reduce our interval such that it always has a unique minimizer in our domain.
Algorithm to find the minima of :
Our goal is to reduce the domain to such that:
- If our new interval would be
- If our new interval would be
We select as interior points to by choosing a and setting:
The challenging part is to select a such that we ensure symmetry i.e. after each iteration we reduce the interval by the same factor, which gives us the indentity . Hence,
As the interval gets reduced by a fixed factor each time, it can be observed that the method is linearly convergent. The number is the inverse of the “Golden-Ratio” and hence this algorithm is named Golden Section Search.
In golden section search, we do not need to evaluate any derivatives of . At each iteration we need and , but one of or will be the same as the previous iteration, so it only requires 1 additional function evaluation per iteration (after the first iteration).
Optimization in N Dimensions
Steepest Descent
The negative of the gradient of a differentiable function points downhill i.e. towards points in the domain having lower values. This hints us to move in the direction of while searching for the minimum until we reach the point where . Therefore, at a point the direction ‘’’’ is called the direction of steepest descent.
We know the direction we need to move to approach the minimum but we still do not know the distance we need to move in order to approach the minimum. If was our earlier point then we select the next guess by moving it in the direction of the negative gradient:
The next problem would be to find the , and we use the 1-dimensional optimization algorithms to find the required . Hence, the problem translates to:
The steepest descent algorithm can be summed up in the following function:
import numpy.linalg as la
import scipy.optimize as opt
import numpy as np
def obj_func(alpha, x, s):
# code for computing the objective function at (x+alpha*s)
return f_of_x_plus_alpha_s
def gradient(x):
# code for computing gradient
return grad_x
def steepest_descent(x_init):
x_new = x_init
x_prev = np.random.randn(x_init.shape[0])
while(la.norm(x_prev - x_new) > 1e-6):
x_prev = x_new
s = -gradient(x_prev)
alpha = opt.minimize_scalar(obj_func, args=(x_prev, s)).x
x_new = x_prev + alpha*s
return x_new
The steepest descent method converges linearly.
Newton’s Method
Newton’s Method in dimensions is similar to Newton’s method for root finding in dimensions, except we just replace the -dimensional function by the gradient and the Jacobian matrix by the Hessian matrix. We can arrive at the result by considering the Taylor expansion of the function.
We solve for for . Hence the equation can be translated as:
The Newton’s Method can be expressed as a python function as follows:
import numpy as np
def hessian(x):
# Computes the hessian matrix corresponding the given objective function
return hessian_matrix_at_x
def gradient(x):
# Computes the gradient vector corresponding the given objective function
return gradient_vector_at_x
def newtons_method(x_init):
x_new = x_init
x_prev = np.random.randn(x_init.shape[0])
while(la.norm(x_prev-x_new)>1e-6):
x_prev = x_new
s = -la.solve(hessian(x_prev), gradient(x_prev))
x_new = x_prev + s
return x_new
Review Questions
- See this review link
ChangeLog
- 2020-08-08 Jerry Yang jiayiy7@illinois.edu: adds unimodal examples
- 2020-04-26 Mariana Silva mfsilva@illinois.edu: small text revision
- 2018-4-25 Adam Stewart adamjs5@illinois.edu: fixes missing parenthesis in
newtons_method - 2017-11-25 Adam Stewart adamjs5@illinois.edu: fixes missing partial in Hessian matrix
- 2017-11-20 Kaushik Kulkarni kgk2@illinois.edu: fixes table formatting
- 2017-11-20 Nate Bowman nlbowma2@illinois.edu: adds review questions
- 2017-11-20 Erin Carrier ecarrie2@illinois.edu: removes Gauss-Newton/LM, minor rewording and small changes throughout
- 2017-11-20 Kaushik Kulkarni kgk2@illinois.edu and Arun Lakshmanan lakshma2@illinois.edu: first full draft
- 2017-10-17 Luke Olson lukeo@illinois.edu: outline