Floating Point Representation
Learning Objectives
- Represent a real number in a floating point system
- Measure the error in rounding numbers using the IEEE-754 floating point standard
- Compute the memory requirements of storing integers versus double precision
- Define Machine Epsilon
- Identify the smallest representable floating point number
- Predict the outcome of loss of significance in floating point arithmetic
Links and Other Content
Number Systems and Bases
There are a variety of number systems in which a number can be represented. In the common base 10 (decimal) system each digit takes on one of 10 values, from 0 to 9. In base 2 (binary), each digit takes on one of 2 values, 0 or 1.
For a given \(\beta\), in the \(\beta\)-system we have: \[(a_n \ldots a_2 a_1 a_0 . b_1 b_2 b_3 b_4 \dots)_{\beta} = \sum_{k=0}^{n} a_k \beta^k + \sum_{k=0}^\infty b_k \beta{-k}.\]
Some common bases used for numbering systems are:
- decimal: \(\beta=10\)
- binary: \(\beta=2\)
- octal: \(\beta=8\)
- hexadecimal \(\beta=16\)
Converting Integers Between Decimal and Binary
Modern computers use transistors to store data. These transistors can either be ON (1) or OFF (0). In order to store integers in a computer, we must first convert them to binary. For example, the binary representation of 23 is \((10111)_2\).
Converting an integer from binary representation (base 2) to decimal representation (base 10) is easy. Simply multiply each digit by increasing powers of 2 like so:
\[(10111)_2 = 1 \cdot 2^4 + 0 \cdot 2^3 + 1 \cdot 2^2 + 1 \cdot 2^1 + 1 \cdot 2^0 = 23\]
Converting an integer from decimal to binary is a similar process, except instead of multiplying by 2 we will be dividing by 2 and keeping track of the remainder:
\[\begin{align*} 23 // 2 &= 11\ \mathrm{rem}\ 1 \\ 11 // 2 &= 5\ \mathrm{rem}\ 1 \\ 5 // 2 &= 2\ \mathrm{rem}\ 1 \\ 2 // 2 &= 1\ \mathrm{rem}\ 0 \\ 1 // 2 &= 0\ \mathrm{rem}\ 1 \\ \end{align*}\]
Thus, $$(23)_{10}$$ becomes \((10111)_2\) in binary.
Converting Fractions Between Decimal and Binary
Real numbers add an extra level of complexity. Not only do they have a leading integer, they also have a fractional part. For now, we will represent a decimal number like 23.625 as \((10111.101)_2\). Of course, the actual machine representation depends on whether we are using a fixed point or a floating point representation, but we will get to that in later sections.
Converting a number with a fractional portion from binary to decimal is similar to converting to an integer, except that we continue into negative powers of 2 for the fractional part:
\[(10111.101)_2 = 1 \cdot 2^4 + 0 \cdot 2^3 + 1 \cdot 2^2 + 1 \cdot 2^1 + 1 \cdot 2^0 + 1 \cdot 2^{-1} + 0 \cdot 2^{-2} + 1 \cdot 2^{-3} = 23.625\]
To convert a decimal fraction to binary, first convert the integer part to binary as previously discussed. Then, take the fractional part (ignoring the integer part) and multiply it by 2. The resulting integer part will be the binary digit. Throw away the integer part and continue the process of multiplying by 2 until the fractional part becomes 0. For example:
\[\begin{align*} 23 &= (10111)_2 \\ 2 \cdot .625 &= 1.25 \\ 2 \cdot .25 &= 0.50 \\ 2 \cdot .5 &= 1.0 \\ \end{align*}\]
By combining the integer and fractional parts, we find that \(23.625 = (10111.101)_2\).
Not all fractions can be represented in binary using a finite number of digits. For example, if you try the above technique on a number like 0.1, you will find that the remaining fraction begins to repeat:
\[\begin{align*} 2 \cdot .1 &= 0.2 \\ 2 \cdot .2 &= 0.4 \\ 2 \cdot .4 &= 0.8 \\ 2 \cdot .8 &= 1.6 \\ 2 \cdot .6 &= 1.2 \\ 2 \cdot .2 &= 0.4 \\ 2 \cdot .4 &= 0.8 \\ 2 \cdot .8 &= 1.6 \\ 2 \cdot .6 &= 1.2 \\ \end{align*}\]
As you can see, the decimal 0.1 will be represented in binary as the infinitely repeating series \((0.00011001100110011...)_2\). The exact number of digits that get stored in a floating point number depends on whether we are using single precision or double precision.
Floating Point Numbers
The floating point representation of a binary number is similar to scientific notation for decimals. Much like you can represent 23.625 as:
\[2.3625 \cdot 10^1\]
you can represent \((10111.101)_2\) as:
\[1.0111101 \cdot 2^4\]
More formally, we can define a floating point number \(x\) as:
\[x = \pm q \cdot 2^m\]
where:
- \(\pm\) is the sign
- \(q\) is the significand
- \(m\) is the exponent
Aside from the special case of zero and subnormal numbers (discussed below), the significand is always in normalized form:
\[q = 1.f\]
where:
- \(f\) is the fractional part
Whenever we store a floating point number, the 1 is assumed. We don't store the entire significand, just the fractional part.
IEEE-754 Single Precision

- 1-bit sign
- 8-bit exponent \(m\)
- 23-bit fractional part \(f\)
The exponent is shifted by 127 to avoid storing a negative sign. Instead of storing \(m\), we store \(m + 127\). Thus, the largest possible exponent is 127, and the smallest possible exponent is -126.
IEEE-754 Double Precision
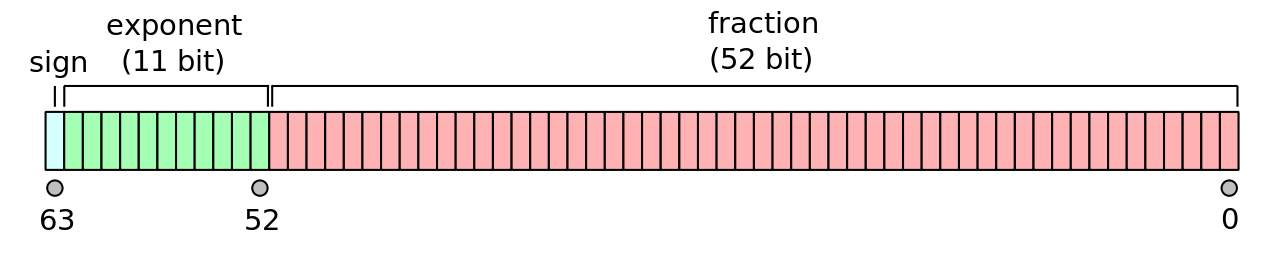
- 1-bit sign
- 11-bit exponent \(m\)
- 52-bit fractional part \(f\)
The exponent is shifted by 1023 to avoid storing a negative sign. Instead of storing \(m\), we store \(m + 1023\). Thus, the largest possible exponent is 1023, and the smallest possible exponent is -1022.
Corner Cases in IEEE-754
There are several corner cases that arise in floating point representations.
Zero
In our definition of floating point numbers above, we said that there is always a leading 1 assumed. This is true for most floating point numbers. A notable exception is zero. In order to store zero as a floating point number, we store all zeros for the exponent and all zeros for the fractional part. Note that there can be both +0 and -0 depending on the sign bit.
Infinity
If a floating point calculation results in a number that is beyond the range of possible numbers in floating point, it is considered to be infinity. We store infinity with all ones in the exponent and all zeros in the fractional. \(+\infty\) and \(-\infty\) are distinguished by the sign bit.
NaN
Arithmetic operations that result in something that is not a number are represented in floating point with all ones in the exponent and a non-zero fractional part.
Floating Point Number Line
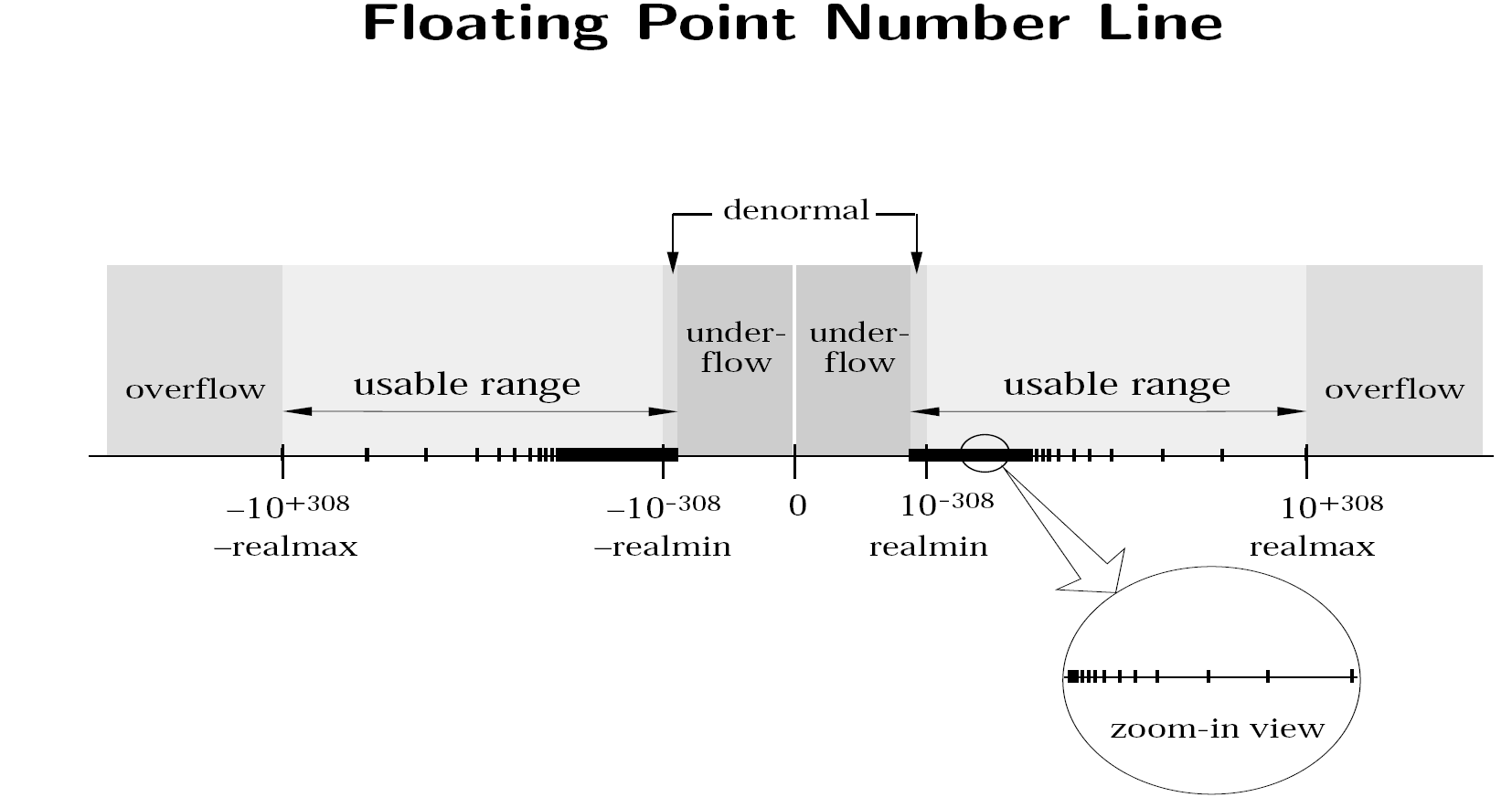
The above image shows the number line for the IEEE-754 floating point system.
Subnormal Numbers
A normal number is defined as a floating point number with a 1 at the start of the significand. Thus, the smallest normal number in double precision is \(1.000... \cdot 2^{-1022}\). The smallest representable normal number is called the underflow level, or UFL.
However, we can go even smaller than this by removing the restriction that the first number of the significand must be a 1. These numbers are known as subnormal, and are stored with all zeros in the exponent. Technically, zero is also a subnormal number.
It is important to note that subnormal numbers do not have as many significant digits as normal numbers.
Rounding Options in IEEE-754
Not all real numbers can be stored exactly as floating point numbers. These numbers are rounded to a nearby floating point number, resulting in roundoff-error. IEEE-754 doesn't specify exactly how to round floating point numbers, but there are several different options:
- round to the next nearest floating point number (preferred)
- round towards zero
- round up
- round down
Machine Epsilon
Machine epsilon (\(\epsilon_m\)) is defined as the distance (gap) between 1 and the next largest floating point number.
For IEEE-754 single precision, \(\epsilon_m = 2^{-23}\), as shown by:
1 = 1.00000000000000000000000
1 + epsilon_m = 1.00000000000000000000001
^ ^
2^0 2^(-23)
For IEEE-754 double precision, \(\epsilon_m = 2^{-52}\), as shown by:
1 = 1.0000000000000000000000000000000000000000000000000000
1 + epsilon_m = 1.0000000000000000000000000000000000000000000000000001
^ ^
2^0 2^(-52)
In programming languages these values are typically available as predefined constants. For example, in C, these constants are FLT_EPSILON and DBL_EPSILON and are defined in the float.h library. In Python you can access these values with the code snippet below.
import numpy as np
# Single Precision
eps_single = np.finfo(np.float32).eps
print("Single precision machine eps = {}".format(eps_single))
# Double Precision
eps_double = np.finfo(np.float64).eps
print("Double precision machine eps = {}".format(eps_double))
Note: There are many definitions of machine epsilon that are used in various resources, such as the smallest number such that \(\text{fl}(1 + \epsilon_m) \ne 1\). These other definitions may give slightly different values from the definition above depending on the rounding mode. We will always use the values from the "gap" definition above.
Relative Error in Floating Point Representations
Machine epsilon can be used to bound the relative error in representing a real number as a machine number. In particular,
\[\frac{|x - \text{fl}(x)|}{|x|} \le \epsilon_{m}.\]
Floating Point Addition
Adding two floating point numbers is easy. The basic idea is:
- Bring both numbers to a common exponent
- Do grade-school addition from the front, until you run out of digits in your system
- Round the result
For example, in order to add \(a = (1.101)_2 \cdot 2^1\) and \(b = (1.001)_2 \cdot 2^{-1}\) in a floating point system with only 3 bits in the fractional part, this would look like:
\[\begin{align*} a &= 1.101 \cdot 2^1 \\ b &= 0.01001 \cdot 2^1 \\ a + b &= 1.111 \cdot 2^1 \\ \end{align*}\]
You'll notice that we added two numbers with 4 significant digits, and our result also has 4 significant digits. There is no loss of significant digits with floating point addition.
Floating Point Subtraction and Catastrophic Cancellation
Floating point subtraction works much the same was that addition does. However, problems occur when you subtract two numbers of similar magnitude.
For example, in order to subtract \(b = (1.1010)_2 \cdot 2^1\) from \(a = (1.1011)_2 \cdot 2^1\), this would look like:
\[\begin{align*} a &= 1.1011???? \cdot 2^1 \\ b &= 1.1010???? \cdot 2^1 \\ a - b &= 0.0001???? \cdot 2^1 \\ \end{align*}\]
When we normalize the result, we get \(1.???? \cdot 2^{-3}\). There is no data to indicate what the missing digits should be. Although the floating point number will be stored with 4 digits in the fractional, it will only be accurate to a single significant digit. This loss of significant digits is known as catastrophic cancellation.
Review Questions
- Convert a decimal number to binary.
- Convert a binary number to decimal.
- What are the differences between floating point and fixed point representation?
- Given a real number, how would you store it as a machine number?
- Given a real number, what is the rounding error involved in storing it as a machine number? What is the relative error?
- Explain the different parts of a floating-point number: sign, significand, and exponent.
- How is the exponent of a machine number actually stored?
- What is machine epsilon?
- What is underflow (UFL)?
- What is overflow?
- Why is underflow sometimes not a problem?
- Given a toy floating-point system, determine machine epsilon and UFL for that system.
- How can we bound the relative error of representing a real number as a normalized machine number?
- How do you store zero as a machine number?
- What is cancellation? Why is it a problem?
- What types of operations lead to catostrophic cancellation?
- Given two different equations for evaluating the same value, can you identify which is more accurate for certain x and why?
- What are subnormal numbers?
- How are subnormal numbers represented in a machine?
- Why are subnormal numbers sometimes helpful?
- What are some drawbacks to using subnormal numbers?
ChangeLog
- 2017-11-19 Matthew West : addition of machine epsilon diagrams
- 2017-11-18 Erin Carrier : updates machine eps def
- 2017-11-15 Erin Carrier : fixes typo in converting integers
- 2017-11-14 Erin Carrier : clarifies when stored normalized
- 2017-11-13 Erin Carrier : updates machine epsilon definition, fixes inconsistent capitalization
- 2017-11-12 Erin Carrier : minor fixes throughout, adds changelog, adds section on number systems in different bases
- 2017-11-01 Adam Stewart : first complete draft
- 2017-10-16 Luke Olson : outline