Learning Objectives
- Practice identifying potential errors in an input dataset
- Implement two sorting methods and measure their efficiency on multiple datasets
- Analyze the given datasets to identify peak pollution times and values
- Practice a recursive algorithm that requires tracking recursive information
You will only need to submit the following files on Gradescope:
sort.py
You will only need to edit the following:
loadPoll()bubbleSort()mergeSort()bubbleSortBigO()mergeSortBigO()maxPollutionTimes()realWorldOutlier()
Assignment Description
As part of a research initiative to better understand causes and symptoms of pollution on air quality, you and your team have placed sensors all around the city, each one set up to record the levels of pollutants with diameters 10 and smaller (Particular Matter or PM 10) and pollutants with diameter 2.5 and smaller (PM25). You imagined that the data would be perfect and easy to analyze, but it couldn’t be further from the truth! Not only are some of your sensors faulty but almost none of them are correctly measuring every interval.
Thankfully you had enough sensors that you were able to gather at least one unique value for every hourly timestamp but because you had to aggregate them from so many different sources, the input data isn’t properly ordered. Your job mirrors that of a conventional data science project – you must clean up the input data, read and store it in the appropriate data structure (here a list of objects), and analyze the data to find both peak and minimum pollution times (here ‘analysis’ is done through sorting).
NOTE: The data provided in this mp is fake but it is built to be a simplified form of real world day (and contains a ‘clean’ version of a real-world signal for ease of detection.) For those interested, the inspiration for this mp was found on Kaggle.
Part 1: Parsing pollution data
List[poll_stamp] loadPoll(inFile)
# Input:
# inFile, an input file storing time-stamped pollution data as a CSV
# Output:
# a list containing a poll_stamp object for every non-empty line in the CSV
The input dataset for this mp is once again a csv-formatted file consisting of three columns:
- The first column contains the timestamp data (which for convenience has already been converted from datetimes to hours after the starting measurement). As the input files span for multiple days, this implies that time point 0 and time point 24 are both 12:00 AM, just for different days.
- The second column contains the PM10 recording for a particular timestamp. PM10 will be the primary measure used to detect pollution for this assignment.
- The third column contains the PM25 recording for a particular timestamp. Note that PM25 actually stands for pollutants of diameter 2.5 and smaller (not diameter 25 or smaller!).
Since there is no obvious ‘ground truth’ for what pollution levels at a particular location will be at a particular time (and the data provided has already been ‘stripped’ of missing data rows), the only data cleaning that needs to be handled are instances where the input data is impossible. In this case, it is impossible for there to be more particles smaller than 2.5 than there are particles smaller than 10 (since PM10 includes all PM25). Your solution must be able to find and remove these faulty rows.
Hint: To help you write code and debug in stages, only the csvs labeled with errors actually contain these errors.
Part 2: Sorting pollution Data
There are a great number of possible sorting algorithms, including many complex but powerful sorting methods that are significantly better than those covered in class. However, for the purpose of building a strong algorithmic foundation, here we will look at just two methods – an algorithm which takes a variable amount of time based on the input data (even with a fixed size) and an algorithm that will always take a fixed amount of time (for a given input size). It is up to you to determine which method is best for a given situation.
You are encouraged to use some of the smaller test files to debug your code. In particular, poll_12_1off is a great first file to use as it contains only a single row out of order. Use this to make sure you are correctly counting the number of swaps or replacements your algorithms are taking in sort. (My implementation takes 10 swaps for bubbleSort() and 44 replacements for mergeSort() when sorting by timestamp on this dataset).
bubbleSort()
int bubbleSort(List[poll_stamp] inList, int iVal)
# Input:
# inList, an input list storing poll_stamp objects
# iVal, an input integer defining which poll_stamp value is being sorted on
# Output:
# an integer recording the number of times a swap was made
# NOTE: a swap constitutes two edits to the list but is only counted once
Bubble sort works by repeatedly comparing an item in this list with its subsequent neighbor and then swapping their positions if the lower index value is larger. By doing this for every pair in an iteration, the largest number in the list will inevitably end up in the last position. The second iteration will then repeat the process for the remaining n-1 values.
A more in-depth description of implementation:
- Starting from index i = 0, compare values at i and i+1. If i is larger, swap values.
- Increment i and repeat (1) until i = n-1.
- Let k = 1 and repeat (2) starting from 0 but stopping at i = n - 1 - k
Each iteration of (2) moves at least one value into the correct final position. If an entire iteration is performed without a single swap, the algorithm can terminate early (as all value are in the right place).
A visual example of this process is below (taken from Wikipedia):
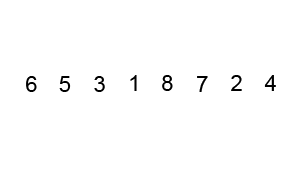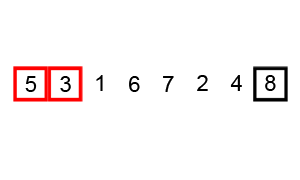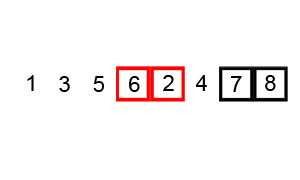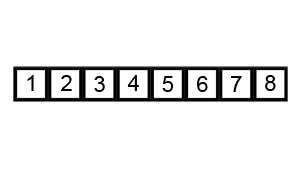
NOTE: A part of the implementation of this algorithm is to accurately track the number of swaps performed using Bubble sort. Every time you swap a value in (1), you must increment a counter and return that count at the end of the algorithm.
mergeSort()
int merge(List[poll_stamp] inList, int iVal)
# Input:
# inFile, an input string storing the path and filename of an input .csv file
# Output:
# A TrainCar object storing the head (first car) listed in the file
# The TrainCar object should be a complete in-order linked list of all valid cars
# in the input file, including corrections made when possible.
Merge sort is a divide and conquer algorithm where the list elements are recursively divided until they are sorted (all size one lists are sorted). The lists are then merged together to preserve sorted order until the full list has been reconstructed.
A more in-depth description of implementation:
Base Case
- When the input list is of size one, the list is sorted.
Recursive Step
- Divide the input list into two roughly equal sublists.
- Run mergeSort on both sublists.
- Merge the two sorted lists returned by (2).
Merge Algorithm
- Track three list indices
i,j,k = 0(one for each sublist being merged and one for the input list being sorted) - While both lists contain values that still need to be merged, replace the value of
inList[k]with eitherl1[i]orl2[j], based on whichever value is smaller. Increment k as well as eitheriorjbased on whichever value was chosen. (On a tie, favor the ‘first’ listl1[i]) - When one list is exhausted, add the remainder of the other sublist to
inList. As both sublists are sorted, the order remains sorted.
A visual example of this process is below (taken from Wikipedia). Use this animation for conceptual understanding not a guideline for implementation. The order in which the recursion rebuilds the list may vary by your implementation details (and likely won’t match this animation):
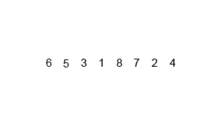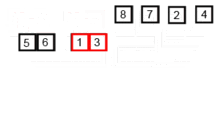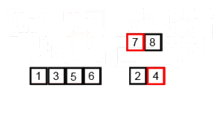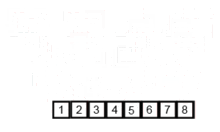
NOTE: You are modifying the input inList rather than building a new list.
NOTE: A part of the implementation of this algorithm is to accurately track the number of list replacements performed during the merge step. Every time you replace a value of inList with its properly sorted equivalent, you must increment a counter and return that count at the end of the algorithm. Be sure to include the number of replacements done at every recursive step of the process (the sorted merge of all sublists).
Part 3: Analyze your algorithms and the data
To assist you in developing your algorithms and for the purpose of analysis, a number of different datasets have been provided. You are encouraged to explore the different datasets (which are all synthetically generated to share a consistent underlying pattern but contain variation) to help you answer the following questions.
BigO analysis
Answer the questions described by bubbleSortBigO() and mergeSortBigO(). Both should be done with a manual return value corresponding to the correct multiple choice question.
As a larger analysis of these two methods – if you knew the data size and could see how ordered or unordered the data was prior to running a sorting algorithm, when would you prefer to use bubbleSort? When would you prefer to use mergeSort? (You do not need to write up anything answering these questions, but should be prepared to discuss your thoughts in class)
Consider: While this question is focused on the efficiency of the algorithms in terms of time, what about the efficiency of the algorithm in terms of memory? Is one better than the other?
peakTimes and peakPollutions
List[int] maxPollutionTimes(str inFile)
# Input:
# inFile, an input string storing the path and filename of an input .csv file
# Output:
# A list of ints containing the top five peak pollution times in the input dataset
List[float] maxPollutionTimes(str inFile)
# Input:
# inFile, an input string storing the path and filename of an input .csv file
# Output:
# A list of floats containing the minimum five pollution values in the input dataset
Write two short functions that use your implementations of loadPoll and your preferred sorting algorithm to identify either the five times that have peak pollution values (ordered starting with the largest of the five and ending with the smallest) or the five smallest pollution values (ordered starting with the smallest possible value).
Your solution should work for any of the provided datasets (all datasets have more than five rows).
Real World Outlier
The most difficult part of handling real-world data is that it is often impossible to distinguish unexpected results from erroneous results. To ensure that you are not cherry-picking data that fits your interpretation of the results, it is necessary to either include all data (including data which is likely incorrect) or define a systematic or statistical method for removing data. (Good practice suggests that you should define such a method before analyzing the data).
These issues – while very important to data science – are not the focus of CS 277. Nonetheless, as an example of what a probable error would look like, take a second look at dataset poll_72 (NOT poll_72_errors) using any or all of the implemented functions or your own data science skills. Is there a point that stands out as an outlier?
For this question, return the timestamp that you suspect is an outlier. You do not need to write any code to answer this (beyond what you have already written for the assignment and whatever code you used to read the data).