IMPORTANT
You will be using fork() in this MP. You should understand what it means to fork bomb.In 2004, Google developed a general framework for processing large data sets on clusters of computers. We recommend you read the link MapReduce on Wikipedia for some background information. However, we will explain everything you need to know below.
To explain what MapReduce does, we'll use a small dataset (the first few lines of a famous poem by Robert Frost):
Two roads diverged in a yellow wood,
And sorry I could not travel both
And be one traveler, long I stood
And looked down one as far as I could.
|
Data Set #1 Input: "Two roads diverged in a yellow wood," |
Data Set #2 Input: "And sorry I could not travel both" |
Data Set #3 Input: "And be one traveler, long I stood" |
Data Set #4 Input: "And looked down one as far as I could." |
|
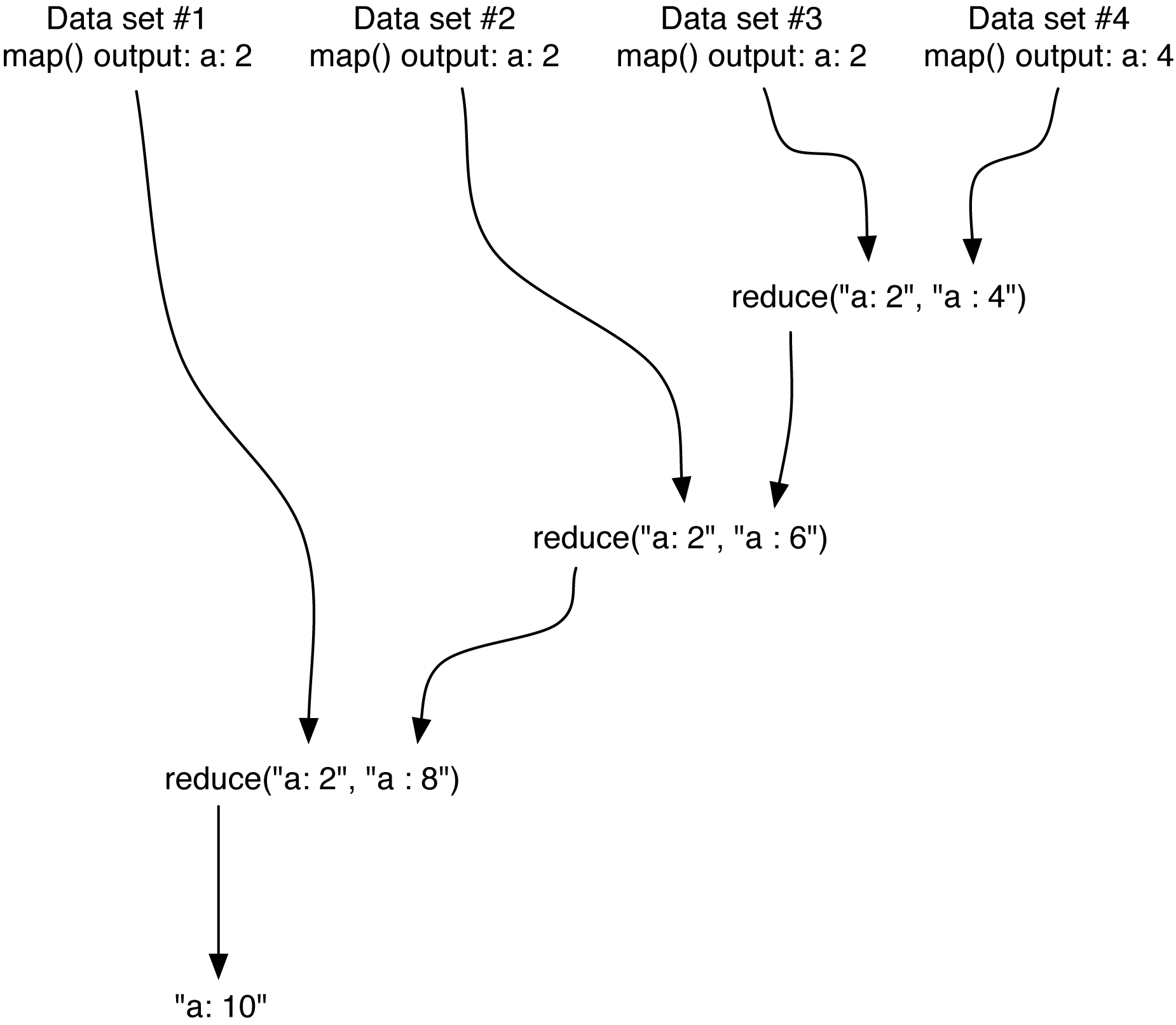
Data Set #1 Input: "Two roads diverged in a yellow wood," pid = 1001 map() Output: a: 2, b: 0, c: 0, d: 4, e: 3, f: 0, g: 1, h: 0, i: 2, j: 0, k: 0, l: 2, m: 0, n: 1, o: 5, p: 0, q: 0, r: 2, s: 1, t: 1, u: 0, v: 1, w: 3, x: 0, y: 1, z: 0 |
Data Set #2 Input: "And sorry I could not travel both" pid = 1002 map() Output: a: 2, b: 1, c: 1, d: 2, e: 1, f: 0, g: 0, h: 1, i: 1, j: 0, k: 0, l: 2, m: 0, n: 2, o: 4, p: 0, q: 0, r: 3, s: 1, t: 3, u: 1, v: 1, w: 0, x: 0, y: 1, z: 0 |
Data Set #3 Input: "And be one traveler, long I stood" pid = 1003 map() Output: a: 2, b: 1, c: 0, d: 2, e: 4, f: 0, g: 1, h: 0, i: 1, j: 0, k: 0, l: 2, m: 0, n: 3, o: 4, p: 0, q: 0, r: 2, s: 1, t: 2, u: 0, v: 1, w: 0, x: 0, y: 0, z: 0 |
Data Set #4 Input: "And looked down one as far as I could." pid = 1004 map() Output: a: 4, b: 0, c: 1, d: 4, e: 2, f: 1, g: 0, h: 0, i: 1, j: 0, k: 1, l: 2, m: 0, n: 3, o: 5, p: 0, q: 0, r: 1, s: 2, t: 0, u: 1, v: 0, w: 1, x: 0, y: 0, z: 0 |
|
Data Set #1 Input: "Two roads diverged in a yellow wood," pid = 1001 map() Output: a: 2, b: 0, c: 0, d: 4, e: 3, f: 0, g: 1, h: 0, i: 2, j: 0, k: 0, l: 2, m: 0, n: 1, o: 5, p: 0, q: 0, r: 2, s: 1, t: 1, u: 0, v: 1, w: 3, x: 0, y: 1, z: 0 |
Data Set #2 Input: "And sorry I could not travel both" pid = 1002 map() Output: a: 2, b: 1, c: 1, d: 2, e: 1, f: 0, g: 0, h: 1, i: 1, j: 0, k: 0, l: 2, m: 0, n: 2, o: 4, p: 0, q: 0, r: 3, s: 1, t: 3, u: 1, v: 1, w: 0, x: 0, y: 1, z: 0 |
Data Set #3 Input: "And be one traveler, long I stood" pid = 1003 map() Output: a: 2, b: 1, c: 0, d: 2, e: 4, f: 0, g: 1, h: 0, i: 1, j: 0, k: 0, l: 2, m: 0, n: 3, o: 4, p: 0, q: 0, r: 2, s: 1, t: 2, u: 0, v: 1, w: 0, x: 0, y: 0, z: 0 |
Data Set #4 Input: "And looked down one as far as I could." pid = 1004 map() Output: a: 4, b: 0, c: 1, d: 4, e: 2, f: 1, g: 0, h: 0, i: 1, j: 0, k: 1, l: 2, m: 0, n: 3, o: 5, p: 0, q: 0, r: 1, s: 2, t: 0, u: 1, v: 0, w: 1, x: 0, y: 0, z: 0 |
|
pid = 1000, worker thread reduce(), reduce(), reduce(), and more reduce()'ing ... ... ... Result: a: 10, b: 2, c: 2, d: 12, e: 10, f: 1, g: 2, h: 1, i: 5, j: 0, k: 1, l: 8, m: 0, n: 9, o: 18, p: 0, q: 0, r: 8, s: 5, t: 6, u: 2, v: 3, w: 4, x: 0, y: 2, z: 0 |
|||
|
|
Besides the tester programs, we provide you a data store libds that allows you to store the results of your MapReduce.
libds includes _get(), _put(), _update(), and _delete() operations that work
similarly to the dictionary you built in MP1. However, these functions provide revision numbers to each key. When you update
or delete a key, you are required to provide the latest revision number you know about. If the revision number does not match
what is in the data store, the update or delete operation will notify you that it could not complete the operation because the
data your program knew about is out of date.
You can find the full API to libds here.
You will find we also provide a read_from_fd() helper function, which we will explain later in this file.
void mapreduce_init(mapreduce_t *mr,
void (*mymap)(int, const char *),
const char *(*myreduce)(const char *, const char *));
This function will be the first call made to the libmapreduce library. You should put any initialization logic here.
(You will likely want to store the mymap and myreduce functions inside mr for later use; mapreduce_init() should not call either of these functions.)
The mymap function pointer is a pointer to a function of the following format:
void map(int fd, const char *data)...where fd is the file descriptor to which map() will write the results of the map() operation on the dataset data. The map() function will always write the (key, value) result to fd in the format key: value\n. As a printf(), this would be:
printf("%s: %s\n", key, value);You do not need to write mymap(), it is passed in as a function pointer to mapreduce_init(). You should note that map() will always close the fd passed to it before returning.
const char *reduce(const char *value1, const char *value2)...where reduce() will return a newly malloc()'d region of memory that is the "reduction" of value1 and value2. Since this function will malloc() new memory, you will need to free() this memory at some later point.
void mapreduce_map_all(mapreduce_t *mr, const char **values);
This is the main function of the first part of this MP. This function will only be called once.
As input to this function, values contains a NULL-terminated array of C-strings. (If there are three values, values[0],
values[1], values[2] will point to C-strings of the data sets each of your map() processes should use and
value[3] will be equal to NULL.) Each of the strings in values will be one data set.
In this function, you must launch one process per data set, and one worker thread (the worker is a thread within the process that called mapreduce_map_all()). Each new process will call map() on one data set. The worker thread will use multiple calls to reduce() to process the data coming back from the map() processes you have launched.
In the description of the map() function, you saw that you will need to pass a file descriptor fd into map(). This
file descriptor should be the writing side of a pipe or fifo that you create in this function. Once fork()'d and the pipe has been
set up, the child process should need to only run code similar to the following:
{
/* child */
map(fd, values[i]);
exit(0); /* exit the child process */
}
int read_from_fd(int fd, char *buffer, mapreduce_t *mr)...this function will read() data from fd and make a call to process_key_value() for each (key, value) that was read. If a line was only partially read, this function will leave the un-processed data in buffer and expects it to be read the next time the function is called. This function expects buffer to initially be of size BUFFER_SIZE + 1 and for buffer[0] == '\0'. Finally, the mr pointer is simply passed-through to process_key_value() as it may be useful to you, as you will need to write the logic to process the key and the value.
void mapreduce_reduce_all(mapreduce_t *mr)
This function will always be called only once, and will always be called sometime after mapreduce_map_all() is called.
This function should block until all map()'ing and reduce()'ing has completed.
const char *mapreduce_get_value(mapreduce_t *mr, const char *result_key)
This function should return the current value of result_key. If the result_key does not exist, return NULL. If a string is returned, it should be a newly allocated string that will need to be freed by the caller. This function may be called at any time, including while the map() processes are working (as more map()'s finish, the value for the same key will likely change between calls to this function).
void mapreduce_destroy(mapreduce_t *mr)
Free all your memory. :) Will always be called last.
void map(int fd, const char *data)
This function should take input from char *data and then map the longest word to the key: long_key. Finally, it should write the key: value pair into the file with the form of long_key: XXXXXXXXX. A word is defined as a contiguous block of alphabetic characters ([a-zA-Z]+). You can use the function isalpha() to test a single character.
const char *reduce(const char *value1, const char *value2)
This function should take two words and reduce to the longer of the two.
make cleanWe provide five test cases:
make
[netid@linux1 mp7]$ ./test1
letters: 8
[netid@linux1 mp7]$ ./test2
letters: 21
[netid@linux1 mp7]$ ./test3
a: 10
b: 2
c: 2
d: 12
e: 10
f: 1
g: 2
h: 1
i: 5
j: 0
k: 1
l: 8
m: 0
n: 9
o: 18
p: 0
q: 0
r: 8
s: 5
t: 6
u: 2
v: 3
w: 4
x: 0
y: 2
z: 0
[netid@linux1 mp7]$ ./test4
the: 1804
and: 912
alice: 385
some-word-that-wont-exist: (null)
[netid@linux1 mp7]$ ./test5
Sleeping for 6 seconds (job #1)...
Sleeping for 5 seconds (job #2)...
Sleeping for 4 seconds (job #3)...
Sleeping for 3 seconds (job #4)...
value: (null)
value: (null)
value: (null)
value: 1
value: 2
value: 3
value: 4
value: 4
value: 4
value: 4
For valgrind memory grading, we will only be testing if your program cleaned up all memory in your original, parent process. You should run:
valgrind --child-silent-after-fork=yes --leak-check=full ./test#...when running your valgrind tests.