CS232 Compilers, Assemblers, and Linkers
Craig Zilles, some figures from Computer Organization & Design
Now that we know what assembly language is all about, and we've looked
at how code primitives (e.g., loops, if, functions) from a high-level
language (HLL) (e.g., C) can be mapped to assembly, we'll elaborate a little
on the process of compilation.
As shown below, the process of compilation from a HLL is a three step
process. First the HLL is "compiled" to assembly, then the assembly
is "assembled" into object files, and finally the object files are
"linked" into an executable.

We can tell a compiler to start and stop at any of these points.
Assume we have a C file named "something.c":
- g++ something.c (compiles, assembles, and links to produce an executable a.out)
- g++ -S something.c (produces an assembly file something.s)
- g++ -c something.c (produces an object file something.o)
- g++ something.s (assembles and links to produce executable a.out)
- g++ something.o (links to produce executable a.out)
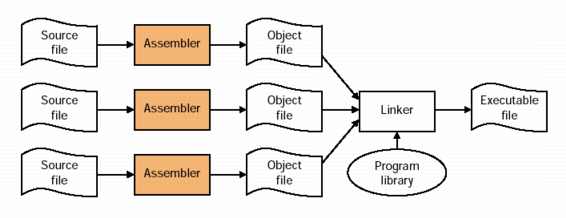
As we are somewhat familiar with the compiler and the assembler at
this point, we'll focus on the linker. The linker enables separate
compilation. As is seen in the next figure, an executable can be made
up of a number of source files which can be compiled and assembled
independently. The linker is responsible for putting those versions
together. This has a number of advantages, including: 1) it enables
distributing libraries in binary form (i.e., no source), including
dynamically linked libraries (DLLs) and when you change your program
you only have to recompile the file that was changed.
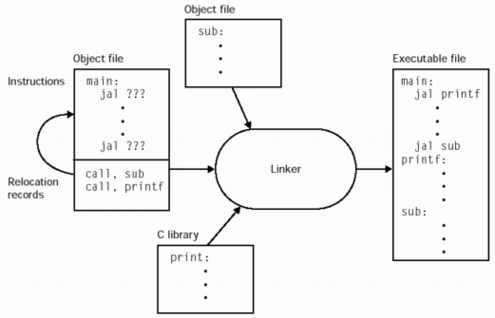
Because the various object files will include references to each
others code and/or data, these will need to be stitched up during link
time. For example in the figure below, the object file that has main
includes calls to functions "sub" and "printf". After concatenating
all of the object files together, the linker uses the "relocation
records" to find all of the addresses that need two be filled in.
Since assembling to machine code removes all traces of labels from the
code, the object file format has to keep these around in a different
place; the symbol table is a list of names and their corresponding
offsets in the text and data segments. An abstract UNIX object file
format is shown below.

A disassembler provides support for translating back from an
object file or executable.
objdump -disassemble a.out (displays assembly for program a.out)
Loaders
Before we can run an executable, we first have to load it into memory.
This is done by the loader, which is generally part of the operating
system. The loader does the following things:
- Allocates memory for the program's execution.
- Copies the text and data segments from the executable into memory.
- Copies program arguments (e.g., command line arguments) onto the stack.
- Initializes registers: sets $sp to point to top of stack, clears the rest.
- Jumps to start routine, which: 1) copies main's arguments off of the stack, and 2) jumps to main.
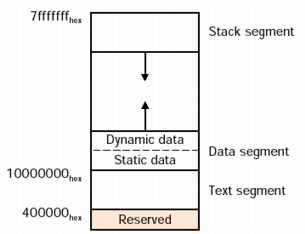
MIPS specifies how our programs will get laid out in memory. The
layout, consisting of 3 segments (text, data, and stack), is shown
below. The "dynamic data" segment is also referred to as the "heap",
the place dynamically allocated memory (from "malloc" and "new") comes
from. This organization enables any division of the dynamically
allocated memory between the heap and the stack. This
explains why the stack grows downward.
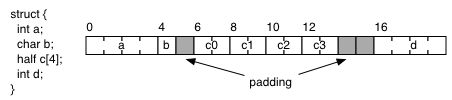
Structs
In previous lectures, we talked about how arrays get laid out.
Structures (and objects for that matter) are very similar, except they
can consist of elements of different sizes. In the example below,
note how padding is inserted to ensure alignment of the various
components. Since in C the structure has to be laid out in the order
specified in the code, bad orderings (like the one below) can lead to
unnecessary padding. How would you reorder the fields to eliminate
the padding?
Why's and How's of Assembly Programming
We write code in assembly in CS 232 to get an understanding of what is
really going on at the machine level, not because it is a good
substitute for high level languages. Actually, quite the opposite.
Most programmers don't write assembly code on a regular basis, for a
number of reasons, including:
- Readability: HLL's are clearer than assembly.
- Portability: Assembly code is ISA specific.
- Productivity: One line of HLL code often takes many lines of assembly, and programmers can write a fixed number of lines of code a day.
That said, there are some good reasons to write code in assembly in
the real world, including:
- Expressiveness: there are some things that cannot be expressed in HLL (e.g., I/O, accesses to special registers).
- Performance/code size: Humans can out code compilers in certain circumstances.
Typically, though, when assembly code is used, the whole application
will not be written in assembly. Instead, a program will mostly be
written in an HLL with a few calls to functions written in assembly.
This makes sense for performance, because empirically most programs
spend around 90% of their time in 10% of the code (the old 90/10
rule). Thus, there is little point coding the other 90% of the code,
which only contributes to 10% of the performance, in assembly.
Typically, it is only the "kernels" of multimedia programs (for
example) that are hand coded in assembly.
In addition to linking your HLL code to functions written in assembly,
some compilers provide support for "inline assembly". The
__asm "function" is interpreted by the compiler, which
substitutes the registers that it assigns for the variables in the HLL
(e.g., a, b, and ret_val) for the place holders (e.g.,
%0, %1, %2) the supplied assembly code.
int
add(int a, int b) { /* return a + b */
int ret_val;
__asm("add %2, %0, %1", a, b, ret_val);
return(ret_val);
}