Lemma 1: If $s_1, s_2, \ldots, s_n$ is a sequence of at least two numbers
for which a property P holds at $s_n$ but not at $s_1$, then
there is an an index $i$ ($1\le i< n$) such that $P$ holds at $s_{i+1}$ but not at $s_i$.
Paraphrase: if a binary state change happens between the start and end of
a sequence, there must be at least one specific
location at which it happens.
Proof: by induction on $n$.
Base case: at $n=2$, we can choose $i$ to be 1. We're given that $P$ is true at $s_2 = s_n$ but not at $s_1$.
Inductive hypothesis: Suppose that the claim holds for sequences of length 2 through $k-1$.
Rest of the inductive step: Let $s_1, s_2, \ldots s_k$ be a sequence of length $k$ for which $P$ holds at
$s_k$ but not at $s_1$.
Case 1: $P$ does not hold at $s_{k-1}$. Since $P$ does hold at $s_k$, we can choose $i=k-1$ as our index.
Case 2: $P$ holds at $s_{k-1}$. Then the sequence $s_1,\ldots, s_{k-1}$ is a sequence of $k-1$ number
such that $P$ holds at the last value but not at the first value. So it's covered by the inductive
hypothesis. So there is an index $i$ such that $P$ holds at $s_{i+1}$ but not at $s_i$.
In both cases, we've found an index $i$ such that $P$ holds at $s_{i+1}$ but not at $s_i$.
Comments
Comment 1: When we applied the inductive hypothesis in case 2, notice that we checked that the smaller
object was of the correct type. Said another way, case 2 was constructed so that the smaller object
must be of the correct type and case 1 is catching the situations where it won't be.
Comment 2: you'll see many variants of this proof. It's similar to
the intermediate value theorem, except that we're dealing with
discrete state changes rather than continuous numerical changes. The
exact property does not matter.
Comment 3: this kind of complex claim is when people stop writing
out the whole claim in the inductive hypothesis. (On examlets, we
try to keep the length of the full, unabbreviated, inductive hypothesis
under control since we require you to write it all out.)
Lemma about strings
Lemma 2: Suppose that $w$ is a string of $a$'s and $b$'s, of length at least 1,
in which the number of $a$'s is one more than the number of $b$'s.
Then we can divide $w$ into
$w = xay$, where string $x$ (and therefore also string $y$) has equal numbers of $a$'s and $b$'s.
To understand where an input string can be divided, it helps to create a sequence of numbers which
shows the difference between the a and b counts as we move through the string.
For example: suppose $w=abababa$. Here is the sequence of letters in $w$ plus the sequence ($s$)
of difference values:
pos: 1 2 3 4 5 6 7
w: a b a b a b a
s: 0 1 0 1 0 1 0 1
pos: 1 2 3 4 5 6 7 8
We can divide the string at a point where the differences go from 0 to 1. In this case,
if we set $x=abab$ and $y=ba$, then $w=xay$.
Or suppose $w = abbabaa$:
pos: 1 2 3 4 5 6 7
w: a b b b a a a
s: 0 1 0 -1 -2 -1 0 1
pos: 1 2 3 4 5 6 7 8
The difference sequence goes from 0 to 1 right near the start.
So if we set $x=\epsilon$ (i.e. the empty string) and $y=bbbaaa$, then $w=xay$.
Proof of lemma 2:
The string $w$ is a sequence of characters $w_1, \ldots, w_n$. Let's define a sequence of numbers
$s_1,\ldots, s_{n+1}$ where $s_k$ is the number of $a$'s minus the number of $b$'s in the string up to, but
not including, character $w_k$.
And $w_{n+1}$ is the difference between the two numbers for the whole string.
Consider the property of being positive. $s_0$ is zero, therefore not positive. Since $w$ contains more
$a$'s than $b$'s, $s_{n+1}$ is positive. So by our Lemma above, there is an index $i$ such that
$s_i$ is not positive but $s_{i+1}$ is positive.
Notice that successive values in $s$ must differ by $\pm 1$. So if
$s_i$ is not positive but $s_{i+1}$ is positive, then we must have
$s_i = 0$ and $s_{i+1} = 1$.
Remember that $s_i$ is the position right before $w_i$.
Since $s_i = 0$
the string from the start up to, but not including, $w_i$ contains equal numbers of $a$'s and $b$'s.
Since $s_i = 1$, $w_i$ is an $a$.
There are three cases:
$i=1$. Then the string $x = \epsilon$ and $y = w_2, \ldots, w_n$.
$i=n$. Then the string $y = \epsilon$ and $x= w_1, \ldots, w_{n-1}$.
$1 < i < n$. Then $x= w_1, \ldots, w_{i-1}$ and $y = w_{i+1}, \ldots, w_n$.
In all three cases, we have found strings $x$ and $y$ such that $w=xay$. This is what we needed to show.
Notice that the same argument will work if we swap the roles of $a$ and $b$ in Lemma 2.
Grammar proofs
Here is a grammar $G$, with start symbol $S$ and terminal symbols $a$ and $b$.
\begin{eqnarray*} S &\rightarrow& a\ S \ b \ S \ \mid \ b\ S\ a \ S\ \mid \ \epsilon \end{eqnarray*}
This grammar generates exactly the set of strings that contain equal numbers of $a$'s and $b$'s.
We can break this into two claims:
Claim A: all strings produced by this grammar contain equal numbers of $a$'s and $b$'s.
Claim B: the grammar produces all strings that contain equal numbers of $a$'s and $b$'s.
Claim A is obviously true, since the grammar rules produce all $a$'s and $b$'s as pairs. A formal
proof would use induction on the height of the grammar trees. There is an example of this type of
proof in the textbook.
It's not at all clear that Claim B is even true, though you might start to suspect it is if you fiddle
around building grammar trees for different example strings.. To prove it, we need to show an algorithm by which
we can create a grammar tree for any input string with equal numbers of $a$'s and $b$'s.
We'll do this by induction on the length of the input string.
Grammar string induction
Claim B: any string with equal numbers of a's and b's can be generated by grammar $G$.
Main concept for proof:
Induction on string length, not induction on tree height.
For each string with equal numbers of a's and b's, you need to show how to build a parse tree.
Proof:
By induction on h, which is the number of a's in the string.
Base Case:
At $h=0$, there is only one string with 0 a's and the same number of b's, i.e. $\epsilon$. It can be generated by $G$
using the rule $S \rightarrow \epsilon$.
Inductive Hypothesis:
Suppose that any string with equal numbers of a's and b's can be
generated by grammar $G$, for strings with $h$ a's (i.e. length $2h$) where
$h=0, 1, \ldots,k-1$ ($k \ge 1$).
Rest of Inductive Step: Let $v$ be a string of length $2k$
with equal numbers of a's and b's. Since $k \ge 1$, there are two
cases.
Case 1: $v$ starts with an a. Then $v = aw$. The number of b's in
$w$ must be one more than the number of a's. Using Lemma 2, we can
divide $w$ as $w=xby$ where $x$ and $y$ each have equal numbers of a's
and b's. So $v=axby$. Since $x$ has equal numbers of a's and b's, we
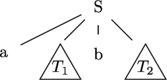
can build a parse tree $T_1$ for $x$. Similarly, we can build a parse
tree $T_2$for $y$. We can join these into a parse tree for $v$ using
the rule $S \rightarrow a\ S \ b \ S$. The top of the tree looks like
this:
Case 2: $v$ starts with a b. Then $v = bw$. The number of a's in $w$
must be one more than the number of b's. Using Lemma 2, we can divide
$w$ as $w=xay$. So $v=bxay$. By the inductive hypothesis, we can
build parse trees for $x$ and $y$. We can join these into a parse
tree for $v$ using the rule $S \rightarrow b\ S \ a \ S$.
In both cases, we can build a parse tree for the string $v$, which is what we needed to show.
Binomial Trees
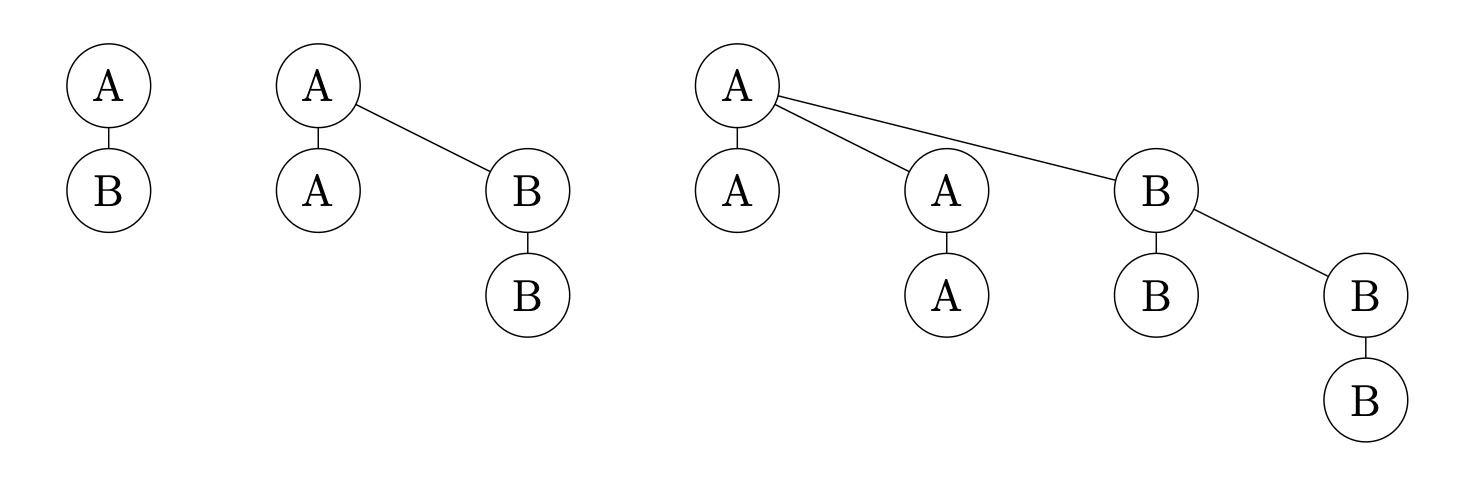
A binomial tree of order $k$ is defined recursively as follows:
A single root node is a binomial tree of order 0.
A binomial tree of order $k$ consists of two
binomial trees of order $k-1$, with the root of the first connected
as the rightmost child of the root of the second.
The following picture shows the binomial trees of order 1, 2, and 3.
The labels on the nodes show how the larger tree is divided into two
lower-order subtrees.
Claim 1: a binomial tree of order $k$ has $2^k$ nodes.
By induction on the order, $k$.
Base base: At $n=0$, we have a binomial tree of order 0, which has $2^0 = 1$ nodes.
Inductive hypothesis: Assume that all trees of order \(n < k\) have $2^n$ nodes.
Rest of the inductive step:
Consider a binomial tree $T$ of order $k$.
By definition, $T$ is composed of two binomial trees of order $k-1$
with no other nodes added or removed. By the inductive hypothesis, each
of these smaller trees has $2^{k-1}$ nodes. Therefore $T$ must have $2^k$ nodes,
which is what we wanted to show.
Claim 2:
a binomial tree of order $k$ has exactly
$\binom{k}{i}$ nodes at level $i$.
We're going to assume that we've already proved two lemmas:
A binomial tree of order $k$ has height $k$.
Pascal's identity,
$\binom{a-1}{b} + \binom{a-1}{b-1} = \binom{a}{b}$
for any positive integers $a$ and $b$ where $b < a$.
Now our main proof:
Proof by induction $k$ which is the order of the tree.
Base case: For $k=0$, we have a binomial tree of order 0. At level 0, this tree has $\binom{0}{0} = 1$ nodes.
Inductive hypothesis: Suppose that a binomial tree of order $n < k$ has
exactly $\binom{n}{i}$ nodes at level $i$.
Now consider a binomial tree $T$ of order $k$.
$T$ contains a binomial tree of order $k-1$ (call it $S_1$)
with another binomial tree (call it $S_2$) of order $k-1$ attached as a child of the root of $S_1$.
There are three parts of $T$ to consider: the top level, the bottom
level, and an arbitrary level in between.
Case 1: level 0, $T$ has only one (root) node. This agrees with the fact that $\binom{k}{0}=1$.
Case 2: level $k$. At this level, $S_1$ doesn't have any more nodes. By the inductive
hypothesis, $S_2$ has $\binom{k-1}{k-1} =1$ node.
Notice that $\binom{k}{k} $ is also equal to 1. So $T$ has $\binom{k}{k} $ at this level, which
is what our claim requires.
Case 3: level $i$, $0 < i < k$.
By the inductive hypothesis, $S_1$ contributes
$\binom{k-1}{i}$ nodes at this level. Because the root of $S_2$ is attached under the root of
$S_1$, the level numbers in $S_2$ are shifted down.
That is, level $i$ in $T$ and $S_1$ corresponds to level $i-1$ inside $S_2$.
So $S_2$ contributes $\binom{k-1}{i-1}$ nodes at this level.
In total, $T$ contains $\binom{k-1}{i} + \binom{k-1}{i-1}$ nodes at level $i$.
By Pascal's identity,
$\binom{k-1}{i} + \binom{k-1}{i-1} = \binom{k}{i}$, which agrees with our claim.